 Evolution of Unix and Unix-like systems | |
| Developer | Ken Thompson, Dennis Ritchie, Brian Kernighan, Douglas McIlroy, and Joe Ossanna at Bell Labs |
|---|---|
| Written in | C and assembly language |
| OS family | Unix |
| Source model | Historically proprietary software, while some Unix projects (including BSD family and illumos) are open-source |
| Initial release | Development started in 1969 First manual published internally in November 1971[1] Announced outside Bell Labs in October 1973[2] |
| Available in | English |
| Kernel type | Varies; monolithic, microkernel, hybrid |
| Influenced by | Multics |
| Default user interface | Command-line interface and Graphical (Wayland and X Window System; Android SurfaceFlinger; macOS Quartz) |
| License | Varies; some versions are proprietary, others are free/open-source software |
| Official website | opengroup |
Unix (/ˈjuːnɪks/; trademarked as UNIX) is a family of multitasking, multiuser computer operating systems that derive from the original AT&T Unix, whose development started in the 1970s at the Bell Labs research center by Ken Thompson, Dennis Ritchie, and others.[3]
Initially intended for use inside the Bell System, AT&T licensed Unix to outside parties in the late 1970s, leading to a variety of both academic and commercial Unix variants from vendors including University of California, Berkeley (BSD), Microsoft (Xenix), Sun Microsystems (SunOS/Solaris), HP/HPE (HP-UX), and IBM (AIX). In the early 1990s, AT&T sold its rights in Unix to Novell, which then sold its Unix business to the Santa Cruz Operation (SCO) in 1995.[4] The UNIX trademark passed to The Open Group, an industry consortium founded in 1996, which allows the use of the mark for certified operating systems that comply with the Single UNIX Specification (SUS). However, Novell continues to own the Unix copyrights, which the SCO Group, Inc. v. Novell, Inc. court case (2010) confirmed.
Unix systems are characterized by a modular design that is sometimes called the "Unix philosophy". According to this philosophy, the operating system should provide a set of simple tools, each of which performs a limited, well-defined function.[5] A unified filesystem (the Unix filesystem) and an inter-process communication mechanism known as "pipes" serve as the main means of communication,[3] and a shell scripting and command language (the Unix shell) is used to combine the tools to perform complex workflows.
Unix distinguishes itself from its predecessors as the first portable operating system: almost the entire operating system is written in the C programming language, which allows Unix to operate on numerous platforms.[6]

Unix was originally meant to be a convenient platform for programmers developing software to be run on it and on other systems, rather than for non-programmers.[7][8][9] The system grew larger as the operating system started spreading in academic circles, and as users added their own tools to the system and shared them with colleagues.[10]
At first, Unix was not designed to be portable[6] or for multi-tasking.[11] Later, Unix gradually gained portability, multi-tasking and multi-user capabilities in a time-sharing configuration. Unix systems are characterized by various concepts: the use of plain text for storing data; a hierarchical file system; treating devices and certain types of inter-process communication (IPC) as files; and the use of a large number of software tools, small programs that can be strung together through a command-line interpreter using pipes, as opposed to using a single monolithic program that includes all of the same functionality. These concepts are collectively known as the "Unix philosophy". Brian Kernighan and Rob Pike summarize this in The Unix Programming Environment as "the idea that the power of a system comes more from the relationships among programs than from the programs themselves".[12]
By the early 1980s, users began seeing Unix as a potential universal operating system, suitable for computers of all sizes.[13][14] The Unix environment and the client–server program model were essential elements in the development of the Internet and the reshaping of computing as centered in networks rather than in individual computers.
Both Unix and the C programming language were developed by AT&T and distributed to government and academic institutions, which led to both being ported to a wider variety of machine families than any other operating system.
The Unix operating system consists of many libraries and utilities along with the master control program, the kernel. The kernel provides services to start and stop programs, handles the file system and other common "low-level" tasks that most programs share, and schedules access to avoid conflicts when programs try to access the same resource or device simultaneously. To mediate such access, the kernel has special rights, reflected in the distinction of kernel space from user space, the latter being a priority realm where most application programs operate.

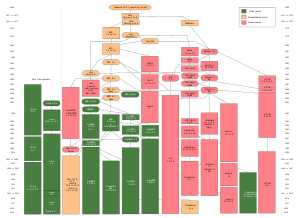
The origins of Unix date back to the mid-1960s when the Massachusetts Institute of Technology, Bell Labs, and General Electric were developing Multics, a time-sharing operating system for the GE-645 mainframe computer.[15] Multics featured several innovations, but also presented severe problems. Frustrated by the size and complexity of Multics, but not by its goals, individual researchers at Bell Labs started withdrawing from the project. The last to leave were Ken Thompson, Dennis Ritchie, Douglas McIlroy, and Joe Ossanna,[11] who decided to reimplement their experiences in a new project of smaller scale. This new operating system was initially without organizational backing, and also without a name.
The new operating system was a single-tasking system.[11] In 1970, the group coined the name Unics for Uniplexed Information and Computing Service as a pun on Multics, which stood for Multiplexed Information and Computer Services. Brian Kernighan takes credit for the idea, but adds that "no one can remember" the origin of the final spelling Unix.[16] Dennis Ritchie,[11] Doug McIlroy,[1] and Peter G. Neumann[17] also credit Kernighan.
The operating system was originally written in assembly language, but in 1973, Version 4 Unix was rewritten in C.[11] Version 4 Unix, however, still had many PDP-11 dependent codes, and was not suitable for porting. The first port to another platform was made five years later (1978) for the Interdata 8/32.[18]
In 1974, Ken Robinson of the Department of Computer Science at University of New South Wales (UNSW) in Australia requested a copy of Unix for their PDP-11/40 minicomputer from Dennis Ritchie at Bell Labs. This 1975 installation made UNSW the first university outside the United States to run Unix.[19]
Bell Labs produced several versions of Unix that are collectively referred to as Research Unix. In 1975, the first source license for UNIX was sold to Donald B. Gillies at the University of Illinois at Urbana–Champaign Department of Computer Science (UIUC).[20] UIUC graduate student Greg Chesson, who had worked on the Unix kernel at Bell Labs, was instrumental in negotiating the terms of the license.[21]
During the late 1970s and early 1980s, the influence of Unix in academic circles led to large-scale adoption of Unix (BSD and System V) by commercial startups, which in turn led to Unix fragmenting into multiple, similar but often slightly mutually-incompatible systems including DYNIX, HP-UX, SunOS/Solaris, AIX, and Xenix. In the late 1980s, AT&T Unix System Laboratories and Sun Microsystems developed System V Release 4 (SVR4), which was subsequently adopted by many commercial Unix vendors.
In the 1990s, Unix and Unix-like systems grew in popularity and became the operating system of choice for over 90% of the world's top 500 fastest supercomputers,[22] as BSD and Linux distributions were developed through collaboration by a worldwide network of programmers. In 2000, Apple released Darwin, also a Unix system, which became the core of the Mac OS X operating system, later renamed macOS.[23]
Unix operating systems are widely used in modern servers, workstations, and mobile devices.[24]

In the late 1980s, an open operating system standardization effort now known as POSIX provided a common baseline for all operating systems; IEEE based POSIX around the common structure of the major competing variants of the Unix system, publishing the first POSIX standard in 1988. In the early 1990s, a separate but very similar effort was started by an industry consortium, the Common Open Software Environment (COSE) initiative, which eventually became the Single UNIX Specification (SUS) administered by The Open Group. Starting in 1998, the Open Group and IEEE started the Austin Group, to provide a common definition of POSIX and the Single UNIX Specification, which, by 2008, had become the Open Group Base Specification.
In 1999, in an effort towards compatibility, several Unix system vendors agreed on SVR4's Executable and Linkable Format (ELF) as the standard for binary and object code files. The common format allows substantial binary compatibility among different Unix systems operating on the same CPU architecture.
The Filesystem Hierarchy Standard was created to provide a reference directory layout for Unix-like operating systems; it has mainly been used in Linux.
This section does not cite any sources. (January 2017) |
The Unix system is composed of several components that were originally packaged together. By including the development environment, libraries, documents and the portable, modifiable source code for all of these components, in addition to the kernel of an operating system, Unix was a self-contained software system. This was one of the key reasons it emerged as an important teaching and learning tool and has had such a broad influence.[according to whom?]
The inclusion of these components did not make the system large – the original V7 UNIX distribution, consisting of copies of all of the compiled binaries plus all of the source code and documentation occupied less than 10 MB and arrived on a single nine-track magnetic tape. The printed documentation, typeset from the online sources, was contained in two volumes.
The names and filesystem locations of the Unix components have changed substantially across the history of the system. Nonetheless, the V7 implementation is considered by many[who?] to have the canonical early structure:



The Unix system had a significant impact on other operating systems. It achieved its reputation by its interactivity, by providing the software at a nominal fee for educational use, by running on inexpensive hardware, and by being easy to adapt and move to different machines. Unix was originally written in assembly language, but was soon rewritten in C, a high-level programming language.[25] Although this followed the lead of Multics and Burroughs, it was Unix that popularized the idea.
Unix had a drastically simplified file model compared to many contemporary operating systems: treating all kinds of files as simple byte arrays. The file system hierarchy contained machine services and devices (such as printers, terminals, or disk drives), providing a uniform interface, but at the expense of occasionally requiring additional mechanisms such as ioctl and mode flags to access features of the hardware that did not fit the simple "stream of bytes" model. The Plan 9 operating system pushed this model even further and eliminated the need for additional mechanisms.
Unix also popularized the hierarchical file system with arbitrarily nested subdirectories, originally introduced by Multics. Other common operating systems of the era had ways to divide a storage device into multiple directories or sections, but they had a fixed number of levels, often only one level. Several major proprietary operating systems eventually added recursive subdirectory capabilities also patterned after Multics. DEC's RSX-11M's "group, user" hierarchy evolved into VMS directories, CP/M's volumes evolved into MS-DOS 2.0+ subdirectories, and HP's MPE group.account hierarchy and IBM's SSP and OS/400 library systems were folded into broader POSIX file systems.
Making the command interpreter an ordinary user-level program, with additional commands provided as separate programs, was another Multics innovation popularized by Unix. The Unix shell used the same language for interactive commands as for scripting (shell scripts – there was no separate job control language like IBM's JCL). Since the shell and OS commands were "just another program", the user could choose (or even write) their own shell. New commands could be added without changing the shell itself. Unix's innovative command-line syntax for creating modular chains of producer-consumer processes (pipelines) made a powerful programming paradigm (coroutines) widely available. Many later command-line interpreters have been inspired by the Unix shell.
A fundamental simplifying assumption of Unix was its focus on newline-delimited text for nearly all file formats. There were no "binary" editors in the original version of Unix – the entire system was configured using textual shell command scripts. The common denominator in the I/O system was the byte – unlike "record-based" file systems. The focus on text for representing nearly everything made Unix pipes especially useful and encouraged the development of simple, general tools that could be easily combined to perform more complicated ad hoc tasks. The focus on text and bytes made the system far more scalable and portable than other systems. Over time, text-based applications have also proven popular in application areas, such as printing languages (PostScript, ODF), and at the application layer of the Internet protocols, e.g., FTP, SMTP, HTTP, SOAP, and SIP.
Unix popularized a syntax for regular expressions that found widespread use. The Unix programming interface became the basis for a widely implemented operating system interface standard (POSIX, see above). The C programming language soon spread beyond Unix, and is now ubiquitous in systems and applications programming.
Early Unix developers were important in bringing the concepts of modularity and reusability into software engineering practice, spawning a "software tools" movement. Over time, the leading developers of Unix (and programs that ran on it) established a set of cultural norms for developing software, norms which became as important and influential as the technology of Unix itself; this has been termed the Unix philosophy.
The TCP/IP networking protocols were quickly implemented on the Unix versions widely used on relatively inexpensive computers, which contributed to the Internet explosion of worldwide real-time connectivity, and which formed the basis for implementations on many other platforms.
The Unix policy of extensive on-line documentation and (for many years) ready access to all system source code raised programmer expectations, and contributed to the launch of the free software movement in 1983.


In 1983, Richard Stallman announced the GNU (short for "GNU's Not Unix") project, an ambitious effort to create a free software Unix-like system; "free" in the sense that everyone who received a copy would be free to use, study, modify, and redistribute it. The GNU project's own kernel development project, GNU Hurd, had not yet produced a working kernel, but in 1991 Linus Torvalds released the kernel Linux as free software under the GNU General Public License. In addition to their use in the GNU operating system, many GNU packages – such as the GNU Compiler Collection (and the rest of the GNU toolchain), the GNU C library and the GNU core utilities – have gone on to play central roles in other free Unix systems as well.
Linux distributions, consisting of the Linux kernel and large collections of compatible software have become popular both with individual users and in business. Popular distributions include Red Hat Enterprise Linux, Fedora, SUSE Linux Enterprise, openSUSE, Debian GNU/Linux, Ubuntu, Linux Mint, Mandriva Linux, Slackware Linux, Arch Linux and Gentoo.[26]
A free derivative of BSD Unix, 386BSD, was released in 1992 and led to the NetBSD and FreeBSD projects. With the 1994 settlement of a lawsuit brought against the University of California and Berkeley Software Design Inc. (USL v. BSDi) by Unix System Laboratories, it was clarified that Berkeley had the right to distribute BSD Unix for free if it so desired. Since then, BSD Unix has been developed in several different product branches, including OpenBSD and DragonFly BSD.
Linux and BSD are increasingly filling the market needs traditionally served by proprietary Unix operating systems, as well as expanding into new markets such as the consumer desktop and mobile and embedded devices. Because of the modular design of the Unix model, sharing components is relatively common; consequently, most or all Unix and Unix-like systems include at least some BSD code, and some systems also include GNU utilities in their distributions.
In a 1999 interview, Dennis Ritchie voiced his opinion that Linux and BSD operating systems are a continuation of the basis of the Unix design, and are derivatives of Unix:[27]
I think the Linux phenomenon is quite delightful, because it draws so strongly on the basis that Unix provided. Linux seems to be the among the healthiest of the direct Unix derivatives, though there are also the various BSD systems as well as the more official offerings from the workstation and mainframe manufacturers.
In the same interview, he states that he views both Unix and Linux as "the continuation of ideas that were started by Ken and me and many others, many years ago".[27]
OpenSolaris was the free software counterpart to Solaris developed by Sun Microsystems, which included a CDDL-licensed kernel and a primarily GNU userland. However, Oracle discontinued the project upon their acquisition of Sun, which prompted a group of former Sun employees and members of the OpenSolaris community to fork OpenSolaris into the illumos kernel. As of 2014, illumos remains the only active open-source System V derivative.
In May 1975, RFC 681 described the development of Network Unix by the Center for Advanced Computation at the University of Illinois Urbana-Champaign.[28] The Unix system was said to "present several interesting capabilities as an ARPANET mini-host". At the time, Unix required a license from Bell Telephone Laboratories that cost US$20,000 for non-university institutions, while universities could obtain a license for a nominal fee of $150. It was noted that Bell was "open to suggestions" for an ARPANET-wide license.
The RFC specifically mentions that Unix "offers powerful local processing facilities in terms of user programs, several compilers, an editor based on QED, a versatile document preparation system, and an efficient file system featuring sophisticated access control, mountable and de-mountable volumes, and a unified treatment of peripherals as special files." The latter permitted the Network Control Program (NCP) to be integrated within the Unix file system, treating network connections as special files that could be accessed through standard Unix I/O calls, which included the added benefit of closing all connections on program exit, should the user neglect to do so. The modular design of Unix allowed them "to minimize the amount of code added to the basic Unix kernel", with much of the NCP code in a swappable user process, running only when needed.


In October 1993, Novell, the company that owned the rights to the Unix System V source at the time, transferred the trademarks of Unix to the X/Open Company (now The Open Group),[29] and in 1995 sold the related business operations to Santa Cruz Operation (SCO).[30] Whether Novell also sold the copyrights to the actual software was the subject of a federal lawsuit in 2006, SCO v. Novell, which Novell won. The case was appealed, but on August 30, 2011, the United States Court of Appeals for the Tenth Circuit affirmed the trial decisions, closing the case.[31] Unix vendor SCO Group Inc. accused Novell of slander of title.
The present owner of the trademark UNIX is The Open Group, an industry standards consortium. Only systems fully compliant with and certified to the Single UNIX Specification qualify as "UNIX" (others are called "Unix-like").
By decree of The Open Group, the term "UNIX" refers more to a class of operating systems than to a specific implementation of an operating system; those operating systems which meet The Open Group's Single UNIX Specification should be able to bear the UNIX 98 or UNIX 03 trademarks today, after the operating system's vendor pays a substantial certification fee and annual trademark royalties to The Open Group.[32] Systems that have been licensed to use the UNIX trademark include AIX,[33]EulerOS,[34]HP-UX,[35]Inspur K-UX,[36]IRIX,[37]macOS,[38]Solaris,[39]Tru64 UNIX (formerly "Digital UNIX", or OSF/1),[40] and z/OS.[41] Notably, EulerOS and Inspur K-UX are Linux distributions certified as UNIX 03 compliant.[42][43]
Sometimes a representation like Un*x, *NIX, or *N?X is used to indicate all operating systems similar to Unix. This comes from the use of the asterisk (*) and the question mark characters as wildcard indicators in many utilities. This notation is also used to describe other Unix-like systems that have not met the requirements for UNIX branding from the Open Group.
The Open Group requests that UNIX is always used as an adjective followed by a generic term such as system to help avoid the creation of a genericized trademark.
Unix was the original formatting,[disputed ] but the usage of UNIX remains widespread because it was once typeset in small caps (Unix). According to Dennis Ritchie, when presenting the original Unix paper to the third Operating Systems Symposium of the American Association for Computing Machinery (ACM), "we had a new typesetter and troff had just been invented and we were intoxicated by being able to produce small caps".[44] Many of the operating system's predecessors and contemporaries used all-uppercase lettering, so many people wrote the name in upper case due to force of habit. It is not an acronym.[45]
Trademark names can be registered by different entities in different countries and trademark laws in some countries allow the same trademark name to be controlled by two different entities if each entity uses the trademark in easily distinguishable categories. The result is that Unix has been used as a brand name for various products including bookshelves, ink pens, bottled glue, diapers, hair driers and food containers.[46]
Several plural forms of Unix are used casually to refer to multiple brands of Unix and Unix-like systems. Most common is the conventional Unixes, but Unices, treating Unix as a Latin noun of the third declension, is also popular. The pseudo-Anglo-Saxon plural form Unixen is not common, although occasionally seen. Sun Microsystems, developer of the Solaris variant, has asserted that the term Unix is itself plural, referencing its many implementations.[47]
UNIX was created by software developers for software developers, to give themselves an environment they could completely manipulate.
When Unix was created and when it formed its cultural values, there were no end users.
The best thing about UNIX is its portability. UNIX ports across a full range of hardware—from the single-user $5000 IBM PC to the $5 million Cray. For the first time, the point of stability becomes the software environment, not the hardware architecture; UNIX transcends changes in hardware technology, so programs written for the UNIX environment can move into the next generation of hardware.
That then led to Unics (the castrated one-user Multics, so- called due to Brian Kernighan) later becoming UNIX (probably as a result of AT&T lawyers).
Perhaps the most important watershed occurred during 1973, when the operating system kernel was rewritten in C.
The right to use the UNIX Trademark requires the Licensee to pay to The Open Group an additional annual fee, calculated in accordance with the fee table set out below.
UNIX is plural. It is not one operating system but, many implementations of an idea that originated in 1965.
By: Wikipedia.org
Edited: 2021-06-18 14:18:28
Source: Wikipedia.org