A delimiter is a sequence of one or more characters for specifying the boundary between separate, independent regions in plain text, mathematical expressions or other data streams.[1][2][3] An example of a delimiter is the comma character, which acts as a field delimiter in a sequence of comma-separated values. Another example of a delimiter is the time gap used to separate letters and words in the transmission of Morse code.
In mathematics, delimiters are often used to specify the scope of an operation, and can occur both as isolated symbols (e.g., colon in "") and as a pair of opposing-looking symbols (e.g., angled brackets in ).[1]
Delimiters represent one of various means of specifying boundaries in a data stream. Declarative notation, for example, is an alternate method that uses a length field at the start of a data stream to specify the number of characters that the data stream contains.[4]
Delimiters may be characterized as field and record delimiters, or as bracket delimiters.
Field delimiters separate data fields. Record delimiters separate groups of fields.[5]
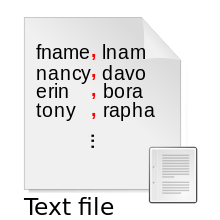
For example, the CSV file format uses a comma as the delimiter between fields, and an end-of-line indicator as the delimiter between records:
fname,lname,age,salary nancy,davolio,33,$30000 erin,borakova,28,$25250 tony,raphael,35,$28700
This specifies a simple flat file database table using the CSV file format.
Bracket delimiters, also called block delimiters, region delimiters, or balanced delimiters, mark both the start and end of a region of text.[6][7]
Common examples of bracket delimiters include:[8]
| Delimiters | Description |
|---|---|
( )
|
Parentheses. The Lisp programming language syntax is cited as recognizable primarily by its use of parentheses.[9] |
{ }
|
Braces (also called curly brackets.[10]) |
[ ]
|
Brackets (commonly used to denote a subscript) |
< >
|
Angle brackets.[11] |
" "
|
commonly used to denote string literals.[12] |
' '
|
commonly used to denote character literals.[12] |
<? ?>
|
used to indicate XML processing instructions.[13] |
/* */
|
used to denote comments in some programming languages.[14] |
<% %>
|
used in some web templates to specify language boundaries. These are also called template delimiters.[15] |
Historically, computing platforms have used certain delimiters by convention.[16][17] The following tables depict a few examples for comparison.
Programming languages (See also, Comparison of programming languages (syntax)).
| String Literal | End of Statement | |
|---|---|---|
| Pascal | singlequote | semicolon |
| Python | doublequote, singlequote | end of line (EOL) |
Field and Record delimiters (See also, ASCII, Control character).
| End of Field | End of Record | End of File | |
|---|---|---|---|
| Unix-like systems including macOS, AmigaOS | Tab | LF | none |
| Windows, MS-DOS, OS/2, CP/M | Tab | CRLF | none (except in CP/M), Control-Z[18] |
| Classic Mac OS, Apple DOS, ProDOS, GS/OS | Tab | CR | none |
| ASCII/Unicode | UNIT SEPARATOR Position 31 (U+001F) |
RECORD SEPARATOR Position 30 (U+001E) |
FILE SEPARATOR Position 28 (U+001C) |
Delimiter collision is a problem that occurs when an author or programmer introduces delimiters into text without actually intending them to be interpreted as boundaries between separate regions.[5][19] In the case of XML, for example, this can occur whenever an author attempts to specify an angle bracket character.
In most file types there is both a field delimiter and a record delimiter, both of which are subject to collision. In the case of comma-separated values files, for example, field collision can occur whenever an author attempts to include a comma as part of a field value (e.g., salary = "$30,000"), and record delimiter collision would occur whenever a field contained multiple lines. Both record and field delimiter collision occur frequently in text files.
In some contexts, a malicious user or attacker may seek to exploit this problem intentionally. Consequently, delimiter collision can be the source of security vulnerabilities and exploits. Malicious users can take advantage of delimiter collision in languages such as SQL and HTML to deploy such well-known attacks as SQL injection and cross-site scripting, respectively.
Because delimiter collision is a very common problem, various methods for avoiding it have been invented. Some authors may attempt to avoid the problem by choosing a delimiter character (or sequence of characters) that is not likely to appear in the data stream itself. This ad hoc approach may be suitable, but it necessarily depends on a correct guess of what will appear in the data stream, and offers no security against malicious collisions. Other, more formal conventions are therefore applied as well.
The ASCII and Unicode character sets were designed to solve this problem by the provision of non-printing characters that can be used as delimiters. These are the range from ASCII 28 to 31.
| ASCII Dec | Symbol | Unicode Name | Common Name | Usage |
|---|---|---|---|---|
| 28 | ␜ | INFORMATION SEPARATOR FOUR | file separator | End of file. Or between a concatenation of what might otherwise be separate files. |
| 29 | ␝ | INFORMATION SEPARATOR THREE | group separator | Between sections of data. Not needed in simple data files. |
| 30 | ␞ | INFORMATION SEPARATOR TWO | record separator | End of a record or row. |
| 31 | ␟ | INFORMATION SEPARATOR ONE | unit separator | Between fields of a record, or members of a row. |
The use of ASCII 31 Unit separator as a field separator and ASCII 30 Record separator solves the problem of both field and record delimiters that appear in a text data stream.[20]
One method for avoiding delimiter collision is to use escape characters. From a language design standpoint, these are adequate, but they have drawbacks:
Escape sequences are similar to escape characters, except they usually consist of some kind of mnemonic instead of just a single character. One use is in string literals that include a doublequote (") character. For example in Perl, the code:
print "Nancy said \x22Hello World!\x22 to the crowd."; ### use \x22
produces the same output as:
print "Nancy said \"Hello World!\" to the crowd."; ### use escape char
One drawback of escape sequences, when used by people, is the need to memorize the codes that represent individual characters (see also: character entity reference, numeric character reference).
In contrast to escape sequences and escape characters, dual delimiters provide yet another way to avoid delimiter collision. Some languages, for example, allow the use of either a single quote (') or a double quote (") to specify a string literal. For example, in Perl:
print 'Nancy said "Hello World!" to the crowd.';
produces the desired output without requiring escapes. This approach, however, only works when the string does not contain both types of quotation marks.
In contrast to escape sequences and escape characters, padding delimiters provide yet another way to avoid delimiter collision. Visual Basic, for example, uses double quotes as delimiters. This is similar to escaping the delimiter.
print "Nancy said ""Hello World!"" to the crowd."
produces the desired output without requiring escapes. Like regular escaping it can, however, become confusing when many quotes are used. The code to print the above source code would look more confusing:
print "print ""Nancy said """"Hello World!"""" to the crowd."""
In contrast to dual delimiters, multiple delimiters are even more flexible for avoiding delimiter collision.[8]:63</ref>
For example, in Perl:
print qq^Nancy doesn't want to say "Hello World!" anymore.^;
print qq@Nancy doesn't want to say "Hello World!" anymore.@;
print qq(Nancy doesn't want to say "Hello World!" anymore.);
all produce the desired output through use of quote operators, which allow any convenient character to act as a delimiter. Although this method is more flexible, few languages support it. Perl and Ruby are two that do.[8]:62</ref>[22]
A content boundary is a special type of delimiter that is specifically designed to resist delimiter collision. It works by allowing the author to specify a sequence of characters that is guaranteed to always indicate a boundary between parts in a multi-part message, with no other possible interpretation.[23]
The delimiter is frequently generated from a random sequence of characters that is statistically improbable to occur in the content. This may be followed by an identifying mark such as a UUID, a timestamp, or some other distinguishing mark. Alternatively, the content may be scanned to guarantee that a delimiter does not appear in the text. This may allow the delimiter to be shorter or simpler, and increase the human readability of the document. (See e.g., MIME, Here documents).
Some programming and computer languages allow the use of whitespace delimiters or indentation as a means of specifying boundaries between independent regions in text.[24]
In specifying a regular expression, alternate delimiters may also be used to simplify the syntax for match and substitution operations in Perl.[25]
For example, a simple match operation may be specified in Perl with the following syntax:
$string1 = 'Nancy said "Hello World!" to the crowd.'; # specify a target string
print $string1 =~ m/[aeiou]+/; # match one or more vowels
The syntax is flexible enough to specify match operations with alternate delimiters, making it easy to avoid delimiter collision:
$string1 = 'Nancy said "http://Hello/World.htm" is not a valid address.'; # target string
print $string1 =~ m@http://@; # match using alternate regular expression delimiter
print $string1 =~ m{http://}; # same as previous, but different delimiter
print $string1 =~ m!http://!; # same as previous, but different delimiter.
A Here document allows the inclusion of arbitrary content by describing a special end sequence. Many languages support this including PHP, bash scripts, ruby and perl. A here document starts by describing what the end sequence will be and continues until that sequence is seen at the start of a new line.[26]
Here is an example in perl:
print <<ENDOFHEREDOC;
It's very hard to encode a string with "certain characters".
Newlines, commas, and other characters can cause delimiter collisions.
ENDOFHEREDOC
This code would print:
It's very hard to encode a string with "certain characters". Newlines, commas, and other characters can cause delimiter collisions.
By using a special end sequence all manner of characters are allowed in the string.
Although principally used as a mechanism for text encoding of binary data, ASCII armoring is a programming and systems administration technique that also helps to avoid delimiter collision in some circumstances.[27][28] This technique is contrasted from the other approaches described above because it is more complicated, and therefore not suitable for small applications and simple data storage formats. The technique employs a special encoding scheme, such as base64, to ensure that delimiter or other significant characters do not appear in transmitted data. The purpose is to prevent multilayered escaping, i.e. for doublequotes.
This technique is used, for example, in Microsoft's ASP.NET web development technology, and is closely associated with the "VIEWSTATE" component of that system.[29]
The following simplified example demonstrates how this technique works in practice.
The first code fragment shows a simple HTML tag in which the VIEWSTATE value contains characters that are incompatible with the delimiters of the HTML tag itself:
<input type="hidden" name="__VIEWSTATE" value="BookTitle:Nancy doesn't say "Hello World!" anymore." />
This first code fragment is not well-formed, and would therefore not work properly in a "real world" deployed system.
To store arbitrary text in an HTML attribute, HTML entities can be used. In this case """ stands in for the double-quote:
<input type="hidden" name="__VIEWSTATE" value="BookTitle:Nancy doesn't say "Hello World!" anymore." />
Alternatively, any encoding could be used that doesn't include characters that have special meaning in the context, such as base64:
<input type="hidden" name="__VIEWSTATE" value="Qm9va1RpdGxlOk5hbmN5IGRvZXNuJ3Qgc2F5ICJIZWxsbyBXb3JsZCEiIGFueW1vcmUu" />
Or percent-encoding:
<input type="hidden" name="__VIEWSTATE" value="BookTitle:Nancy%20doesn%27t%20say%20%22Hello%20World!%22%20anymore." />
This prevents delimiter collision and ensures that incompatible characters will not appear inside the HTML code, regardless of what characters appear in the original (decoded) text.[29]
By: Wikipedia.org
Edited: 2021-06-18 14:09:18
Source: Wikipedia.org

