PostgreSQL (/ˈpoʊstɡrɛsˌkjuːˈɛl/),[13] also known as Postgres, is a free and open-source relational database management system (RDBMS) emphasizing extensibility and SQL compliance. It was originally named POSTGRES, referring to its origins as a successor to the Ingres database developed at the University of California, Berkeley.[14][15] In 1996, the project was renamed to PostgreSQL to reflect its support for SQL. After a review in 2007, the development team decided to keep the name PostgreSQL and the alias Postgres.[16]
PostgreSQL features transactions with Atomicity, Consistency, Isolation, Durability (ACID) properties, automatically updatable views, materialized views, triggers, foreign keys, and stored procedures.[17] It is designed to handle a range of workloads, from single machines to data warehouses or Web services with many concurrent users. It is the default database for macOS Server[18][19][20] and is also available for Windows, Linux, FreeBSD, and OpenBSD.
History
PostgreSQL evolved from the Ingres project at the University of California, Berkeley. In 1982, the leader of the Ingres team, Michael Stonebraker, left Berkeley to make a proprietary version of Ingres.[14] He returned to Berkeley in 1985, and began a post-Ingres project to address the problems with contemporary database systems that had become increasingly clear during the early 1980s. He won the Turing Award in 2014 for these and other projects,[21] and techniques pioneered in them.
The new project, POSTGRES, aimed to add the fewest features needed to completely support data types.[22] These features included the ability to define types and to fully describe relationships – something used widely, but maintained entirely by the user. In POSTGRES, the database understood relationships, and could retrieve information in related tables in a natural way using rules. POSTGRES used many of the ideas of Ingres, but not its code.[23]
Starting in 1986, published papers described the basis of the system, and a prototype version was shown at the 1988 ACM SIGMOD Conference. The team released version 1 to a small number of users in June 1989, followed by version 2 with a re-written rules system in June 1990. Version 3, released in 1991, again re-wrote the rules system, and added support for multiple storage managers[24] and an improved query engine. By 1993, the number of users began to overwhelm the project with requests for support and features. After releasing version 4.2[25] on June 30, 1994 – primarily a cleanup – the project ended. Berkeley released POSTGRES under an MIT License variant, which enabled other developers to use the code for any use. At the time, POSTGRES used an Ingres-influenced POSTQUEL query language interpreter, which could be interactively used with a console application named monitor.
In 1994, Berkeley graduate students Andrew Yu and Jolly Chen replaced the POSTQUEL query language interpreter with one for the SQL query language, creating Postgres95. The monitor console was also replaced by psql. Yu and Chen announced the first version (0.01) to beta testers on May 5, 1995. Version 1.0 of Postgres95 was announced on September 5, 1995, with a more liberal license that enabled the software to be freely modifiable.
On July 8, 1996, Marc Fournier at Hub.org Networking Services provided the first non-university development server for the open-source development effort.[3] With the participation of Bruce Momjian and Vadim B. Mikheev, work began to stabilize the code inherited from Berkeley.
In 1996, the project was renamed to PostgreSQL to reflect its support for SQL. The online presence at the website PostgreSQL.org began on October 22, 1996.[26] The first PostgreSQL release formed version 6.0 on January 29, 1997. Since then developers and volunteers around the world have maintained the software as The PostgreSQL Global Development Group.[2]
The project continues to make releases available under its free and open-source software PostgreSQL License. Code comes from contributions from proprietary vendors, support companies, and open-source programmers.
Multiversion concurrency control (MVCC)
PostgreSQL manages concurrency through multiversion concurrency control (MVCC), which gives each transaction a "snapshot" of the database, allowing changes to be made without affecting other transactions. This largely eliminates the need for read locks, and ensures the database maintains ACID principles. PostgreSQL offers three levels of transaction isolation: Read Committed, Repeatable Read and Serializable. Because PostgreSQL is immune to dirty reads, requesting a Read Uncommitted transaction isolation level provides read committed instead. PostgreSQL supports full serializability via the serializable snapshot isolation (SSI) method.[27]
Storage and replication
Replication
PostgreSQL includes built-in binary replication based on shipping the changes (write-ahead logs (WAL)) to replica nodes asynchronously, with the ability to run read-only queries against these replicated nodes. This allows splitting read traffic among multiple nodes efficiently. Earlier replication software that allowed similar read scaling normally relied on adding replication triggers to the master, increasing load.
PostgreSQL includes built-in synchronous replication[28] that ensures that, for each write transaction, the master waits until at least one replica node has written the data to its transaction log. Unlike other database systems, the durability of a transaction (whether it is asynchronous or synchronous) can be specified per-database, per-user, per-session or even per-transaction. This can be useful for workloads that do not require such guarantees, and may not be wanted for all data as it slows down performance due to the requirement of the confirmation of the transaction reaching the synchronous standby.
Standby servers can be synchronous or asynchronous. Synchronous standby servers can be specified in the configuration which determines which servers are candidates for synchronous replication. The first in the list that is actively streaming will be used as the current synchronous server. When this fails, the system fails over to the next in line.
Synchronous multi-master replication is not included in the PostgreSQL core. Postgres-XC which is based on PostgreSQL provides scalable synchronous multi-master replication.[29] It is licensed under the same license as PostgreSQL. A related project is called Postgres-XL. Postgres-R is yet another fork.[30] Bidirectional replication (BDR) is an asynchronous multi-master replication system for PostgreSQL.[31]
Tools such as repmgr make managing replication clusters easier.
Several asynchronous trigger-based replication packages are available. These remain useful even after introduction of the expanded core abilities, for situations where binary replication of a full database cluster is inappropriate:
Slony-I
Londiste, part of SkyTools (developed by Skype)
Bucardo multi-master replication (developed by Backcountry.com)[32]
SymmetricDS multi-master, multi-tier replication
YugabyteDB is a database which uses the front-end of PostgreSQL with a more NoSQL-like backend. While it can be thought of as a different database, it is essentially PostgreSQL with a different storage backend. It addresses the replication issues with an implementation of the ideas from Google Spanner. Such databases are called NewSQL and include CockroachDB, and TiDB among others.
Indexes
PostgreSQL includes built-in support for regular B-tree and hash table indexes, and four index access methods: generalized search trees (GiST), generalized inverted indexes (GIN), Space-Partitioned GiST (SP-GiST)[33] and Block Range Indexes (BRIN). In addition, user-defined index methods can be created, although this is quite an involved process. Indexes in PostgreSQL also support the following features:
Expression indexes can be created with an index of the result of an expression or function, instead of simply the value of a column.
Partial indexes, which only index part of a table, can be created by adding a WHERE clause to the end of the CREATE INDEX statement. This allows a smaller index to be created.
The planner is able to use multiple indexes together to satisfy complex queries, using temporary in-memory bitmap index operations (useful for data warehouse applications for joining a large fact table to smaller dimension tables such as those arranged in a star schema).
k-nearest neighbors (k-NN) indexing (also referred to KNN-GiST[34]) provides efficient searching of "closest values" to that specified, useful to finding similar words, or close objects or locations with geospatial data. This is achieved without exhaustive matching of values.
Index-only scans often allow the system to fetch data from indexes without ever having to access the main table.
Block Range Indexes (BRIN).
Schemas
In PostgreSQL, a schema holds all objects, except for roles and tablespaces. Schemas effectively act like namespaces, allowing objects of the same name to co-exist in the same database. By default, newly created databases have a schema called public, but any further schemas can be added, and the public schema isn't mandatory.
A search_path setting determines the order in which PostgreSQL checks schemas for unqualified objects (those without a prefixed schema). By default, it is set to $user, public ($user refers to the currently connected database user). This default can be set on a database or role level, but as it is a session parameter, it can be freely changed (even multiple times) during a client session, affecting that session only.
Non-existent schemas listed in search_path are silently skipped during objects lookup.
New objects are created in whichever valid schema (one that presently exists) appears first in the search_path.
Data types
A wide variety of native data types are supported, including:
Boolean
Arbitrary-precision numerics
Character (text, varchar, char)
Binary
Date/time (timestamp/time with/without time zone, date, interval)
Money
Enum
Bit strings
Text search type
Composite
HStore, an extension enabled key-value store within PostgreSQL[35]
Arrays (variable length and can be of any data type, including text and composite types) up to 1 GB in total storage size
Geometric primitives
IPv4 and IPv6 addresses
Classless Inter-Domain Routing (CIDR) blocks and MAC addresses
JavaScript Object Notation (JSON), and a faster binary JSONB (not the same as BSON[36])
In addition, users can create their own data types which can usually be made fully indexable via PostgreSQL's indexing infrastructures – GiST, GIN, SP-GiST. Examples of these include the geographic information system (GIS) data types from the PostGIS project for PostgreSQL.
There is also a data type called a domain, which is the same as any other data type but with optional constraints defined by the creator of that domain. This means any data entered into a column using the domain will have to conform to whichever constraints were defined as part of the domain.
A data type that represents a range of data can be used which are called range types. These can be discrete ranges (e.g. all integer values 1 to 10) or continuous ranges (e.g., any time between 10:00 am and 11:00 am). The built-in range types available include ranges of integers, big integers, decimal numbers, time stamps (with and without time zone) and dates.
Custom range types can be created to make new types of ranges available, such as IP address ranges using the inet type as a base, or float ranges using the float data type as a base. Range types support inclusive and exclusive range boundaries using the [/] and (/) characters respectively. (e.g., [4,9) represents all integers starting from and including 4 up to but not including 9.) Range types are also compatible with existing operators used to check for overlap, containment, right of etc.
User-defined objects
New types of almost all objects inside the database can be created, including:
Casts
Conversions
Data types
Data domains
Functions, including aggregate functions and window functions
Indexes including custom indexes for custom types
Operators (existing ones can be overloaded)
Procedural languages
Inheritance
Tables can be set to inherit their characteristics from a parent table. Data in child tables will appear to exist in the parent tables, unless data is selected from the parent table using the ONLY keyword, i.e. SELECT*FROMONLYparent_table;. Adding a column in the parent table will cause that column to appear in the child table.
Inheritance can be used to implement table partitioning, using either triggers or rules to direct inserts to the parent table into the proper child tables.
As of 2010[update], this feature is not fully supported yet – in particular, table constraints are not currently inheritable. All check constraints and not-null constraints on a parent table are automatically inherited by its children. Other types of constraints (unique, primary key, and foreign key constraints) are not inherited.
Inheritance provides a way to map the features of generalization hierarchies depicted in entity relationship diagrams (ERDs) directly into the PostgreSQL database.
Other storage features
Referential integrity constraints including foreign key constraints, column constraints, and row checks
Binary and textual large-object storage
Tablespaces
Per-column collation
Online backup
Point-in-time recovery, implemented using write-ahead logging
In-place upgrades with pg_upgrade for less downtime (supports upgrades from 8.3.x[37] and later)
Control and connectivity
Foreign data wrappers
PostgreSQL can link to other systems to retrieve data via foreign data wrappers (FDWs).[38]
These can take the form of any data source, such as a file system, another relational database management system (RDBMS), or a web service. This means that regular database queries can use these data sources like regular tables, and even join multiple data-sources together.
Interfaces
For connecting to applications, PostgreSQL includes the built-in interfaces libpq (the official C application interface) and ECPG (an embedded C system). Third-party libraries for connecting to PostgreSQL are available for many programming languages, including C++,[39]Java,[40]Python,[41]Node.js,[42]Go,[43] and Rust.[44]
Procedural languages
Procedural languages allow developers to extend the database with custom subroutines (functions), often called stored procedures. These functions can be used to build database triggers (functions invoked on modification of certain data) and custom data types and aggregate functions.[45] Procedural languages can also be invoked without defining a function, using a DO command at SQL level.[46]
Languages are divided into two groups: Procedures written in safe languages are sandboxed and can be safely created and used by any user. Procedures written in unsafe languages can only be created by superusers, because they allow bypassing a database's security restrictions, but can also access sources external to the database. Some languages like Perl provide both safe and unsafe versions.
PostgreSQL has built-in support for three procedural languages:
Plain SQL (safe). Simpler SQL functions can get expanded inline into the calling (SQL) query, which saves function call overhead and allows the query optimizer to "see inside" the function.
Procedural Language/PostgreSQL (PL/pgSQL) (safe), which resembles Oracle's Procedural Language for SQL (PL/SQL) procedural language and SQL/Persistent Stored Modules (SQL/PSM).
C (unsafe), which allows loading one or more custom shared library into the database. Functions written in C offer the best performance, but bugs in code can crash and potentially corrupt the database. Most built-in functions are written in C.
In addition, PostgreSQL allows procedural languages to be loaded into the database through extensions. Three language extensions are included with PostgreSQL to support Perl, Python (by default discontinued Python 2 is used, even in PostgreSQL 13; Python 3 is also supported by choosing plpython3u)[47] and Tcl. There are external projects to add support for many other languages,[48] including Java, JavaScript (PL/V8), R (PL/R),[49]Ruby, and others.
Triggers
Triggers are events triggered by the action of SQL data manipulation language (DML) statements. For example, an INSERT statement might activate a trigger that checks if the values of the statement are valid. Most triggers are only activated by either INSERT or UPDATE statements.
Triggers are fully supported and can be attached to tables. Triggers can be per-column and conditional, in that UPDATE triggers can target specific columns of a table, and triggers can be told to execute under a set of conditions as specified in the trigger's WHERE clause. Triggers can be attached to views by using the INSTEAD OF condition. Multiple triggers are fired in alphabetical order. In addition to calling functions written in the native PL/pgSQL, triggers can also invoke functions written in other languages like PL/Python or PL/Perl.
Asynchronous notifications
PostgreSQL provides an asynchronous messaging system that is accessed through the NOTIFY, LISTEN and UNLISTEN commands. A session can issue a NOTIFY command, along with the user-specified channel and an optional payload, to mark a particular event occurring. Other sessions are able to detect these events by issuing a LISTEN command, which can listen to a particular channel. This functionality can be used for a wide variety of purposes, such as letting other sessions know when a table has updated or for separate applications to detect when a particular action has been performed. Such a system prevents the need for continuous polling by applications to see if anything has yet changed, and reducing unnecessary overhead. Notifications are fully transactional, in that messages are not sent until the transaction they were sent from is committed. This eliminates the problem of messages being sent for an action being performed which is then rolled back.
Many connectors for PostgreSQL provide support for this notification system (including libpq, JDBC, Npgsql, psycopg and node.js) so it can be used by external applications.
PostgreSQL can act as an effective, persistent "pub/sub" server or job server by combining LISTEN with FOR UPDATE SKIP LOCKED.[50][51][52]
Rules
Rules allow the "query tree" of an incoming query to be rewritten. "Query Re-Write Rules" are attached to a table/class and "Re-Write" the incoming DML (select, insert, update, and/or delete) into one or more queries that either replace the original DML statement or execute in addition to it. Query Re-Write occurs after DML statement parsing, but before query planning.
Encrypted connections via Transport Layer Security (TLS); current versions do not use vulnerable SSL, even with that configuration option[58]
Domains
Savepoints
Two-phase commit
The Oversized-Attribute Storage Technique (TOAST) is used to transparently store large table attributes (such as big MIME attachments or XML messages) in a separate area, with automatic compression.
Embedded SQL is implemented using preprocessor. SQL code is first written embedded into C code. Then code is run through ECPG preprocessor, which replaces SQL with calls to code library. Then code can be compiled using a C compiler. Embedding works also with C++ but it does not recognize all C++ constructs.
Concurrency model
PostgreSQL server is process-based (not threaded), and uses one operating system process per database session. Multiple sessions are automatically spread across all available CPUs by the operating system. Many types of queries can also be parallelized across multiple background worker processes, taking advantage of multiple CPUs or cores.[59] Client applications can use threads and create multiple database connections from each thread.[60]
Security
PostgreSQL manages its internal security on a per-role basis. A role is generally regarded to be a user (a role that can log in), or a group (a role of which other roles are members). Permissions can be granted or revoked on any object down to the column level, and can also allow/prevent the creation of new objects at the database, schema or table levels.
PostgreSQL's SECURITY LABEL feature (extension to SQL standards), allows for additional security; with a bundled loadable module that supports label-based mandatory access control (MAC) based on Security-Enhanced Linux (SELinux) security policy.[61][62]
PostgreSQL natively supports a broad number of external authentication mechanisms, including:
Password: either SCRAM-SHA-256 (since PostgreSQL 10[63]), MD5 or plain-text
Generic Security Services Application Program Interface (GSSAPI)
Security Support Provider Interface (SSPI)
Kerberos
ident (maps O/S user-name as provided by an ident server to database user-name)
The GSSAPI, SSPI, Kerberos, peer, ident and certificate methods can also use a specified "map" file that lists which users matched by that authentication system are allowed to connect as a specific database user.
These methods are specified in the cluster's host-based authentication configuration file (pg_hba.conf), which determines what connections are allowed. This allows control over which user can connect to which database, where they can connect from (IP address, IP address range, domain socket), which authentication system will be enforced, and whether the connection must use Transport Layer Security (TLS).
Standards compliance
PostgreSQL claims high, but not complete, conformance with the SQL standard. One exception is the handling of unquoted identifiers like table or column names. In PostgreSQL they are folded, internally, to lower case characters[64] whereas the standard says that unquoted identifiers should be folded to upper case. Thus, Foo should be equivalent to FOO not foo according to the standard.
Benchmarks and performance
Many informal performance studies of PostgreSQL have been done.[65] Performance improvements aimed at improving scalability began heavily with version 8.1. Simple benchmarks between version 8.0 and version 8.4 showed that the latter was more than 10 times faster on read-only workloads and at least 7.5 times faster on both read and write workloads.[66]
The first industry-standard and peer-validated benchmark was completed in June 2007, using the Sun Java System Application Server (proprietary version of GlassFish) 9.0 Platform Edition, UltraSPARC T1-based Sun Fire server and PostgreSQL 8.2.[67] This result of 778.14 SPECjAppServer2004 JOPS@Standard compares favourably with the 874 JOPS@Standard with Oracle 10 on an Itanium-based HP-UX system.[65]
In August 2007, Sun submitted an improved benchmark score of 813.73 SPECjAppServer2004 JOPS@Standard. With the system under test at a reduced price, the price/performance improved from $84.98/JOPS to $70.57/JOPS.[68]
The default configuration of PostgreSQL uses only a small amount of dedicated memory for performance-critical purposes such as caching database blocks and sorting. This limitation is primarily because older operating systems required kernel changes to allow allocating large blocks of shared memory.[69] PostgreSQL.org provides advice on basic recommended performance practice in a wiki.[70]
In April 2012, Robert Haas of EnterpriseDB demonstrated PostgreSQL 9.2's linear CPU scalability using a server with 64 cores.[71]
Matloob Khushi performed benchmarking between PostgreSQL 9.0 and MySQL 5.6.15 for their ability to process genomic data. In his performance analysis he found that PostgreSQL extracts overlapping genomic regions eight times faster than MySQL using two datasets of 80,000 each forming random human DNA regions. Insertion and data uploads in PostgreSQL were also better, although general searching ability of both databases was almost equivalent.[72]
Platforms
PostgreSQL is available for the following operating systems: Linux (all recent distributions), 64-bit x86 installers available and tested for macOS (OS X)[20] version 10.6 and newer – Windows (with installers available and tested for 64-bit Windows Server 2019 and 2016; some older PostgreSQL versions are tested back to Windows 2012 R1,[73] while for PostgreSQL version 10 and older a 32-bit installer is available and tested down to 32-bit Windows 2008 R1; compilable by e.g. Visual Studio, version 2013 up to the most recent 2019 version) – FreeBSD, OpenBSD,[74]NetBSD, AIX, HP-UX, Solaris, and UnixWare; and not officially tested: DragonFly BSD, BSD/OS, IRIX, OpenIndiana,[75]OpenSolaris, OpenServer, and Tru64 UNIX. Most other Unix-like systems could also work; most modern do support.
PostgreSQL works on any of the following instruction set architectures: x86 and x86-64 on Windows XP (or later) and other operating systems; these are supported on other than Windows: IA-64 Itanium (external support for HP-UX), PowerPC, PowerPC 64, S/390, S/390x, SPARC, SPARC 64, ARMv8-A (64-bit)[76] and older ARM (32-bit, including older such as ARMv6 in Raspberry Pi[77]), MIPS, MIPSel, and PA-RISC. It was also known to work on some other platforms (while not been tested on for years, i.e. for latest versions).[78]
Database administration
See also: Comparison of database tools
Open source front-ends and tools for administering PostgreSQL include:
psql
The primary front-end for PostgreSQL is the psql command-line program, which can be used to enter SQL queries directly, or execute them from a file. In addition, psql provides a number of meta-commands and various shell-like features to facilitate writing scripts and automating a wide variety of tasks; for example tab completion of object names and SQL syntax.
pgAdmin
The pgAdmin package is a free and open-source graphical user interface (GUI) administration tool for PostgreSQL, which is supported on many computer platforms.[79] The program is available in more than a dozen languages. The first prototype, named pgManager, was written for PostgreSQL 6.3.2 from 1998, and rewritten and released as pgAdmin under the GNU General Public License (GPL) in later months. The second incarnation (named pgAdmin II) was a complete rewrite, first released on January 16, 2002. The third version, pgAdmin III, was originally released under the Artistic License and then released under the same license as PostgreSQL. Unlike prior versions that were written in Visual Basic, pgAdmin III is written in C++, using the wxWidgets[80] framework allowing it to run on most common operating systems. The query tool includes a scripting language called pgScript for supporting admin and development tasks. In December 2014, Dave Page, the pgAdmin project founder and primary developer,[81] announced that with the shift towards web-based models, work has begun on pgAdmin 4 with the aim to facilitate cloud deployments.[82] In 2016, pgAdmin 4 was released. pgAdmin 4 backend was written in Python, using Flask and Qt framework.[83]
phpPgAdmin
phpPgAdmin is a web-based administration tool for PostgreSQL written in PHP and based on the popular phpMyAdmin interface originally written for MySQL administration.[84]
PostgreSQL Studio
PostgreSQL Studio allows users to perform essential PostgreSQL database development tasks from a web-based console. PostgreSQL Studio allows users to work with cloud databases without the need to open firewalls.[85]
TeamPostgreSQL
AJAX/JavaScript-driven web interface for PostgreSQL. Allows browsing, maintaining and creating data and database objects via a web browser. The interface offers tabbed SQL editor with autocompletion, row editing widgets, click-through foreign key navigation between rows and tables, favorites management for commonly used scripts, among other features. Supports SSH for both the web interface and the database connections. Installers are available for Windows, Macintosh, and Linux, and a simple cross-platform archive that runs from a script.[86]
LibreOffice, OpenOffice.org
LibreOffice and OpenOffice.org Base can be used as a front-end for PostgreSQL.[87][88]
pgBadger
The pgBadger PostgreSQL log analyzer generates detailed reports from a PostgreSQL log file.[89]
pgDevOps
pgDevOps is a suite of web tools to install & manage multiple PostgreSQL versions, extensions, and community components, develop SQL queries, monitor running databases and find performance problems.[90]
Adminer
Adminer is a simple web-based administration tool for PostgreSQL and others, written in PHP.
pgBackRest
pgBackRest is a backup and restore tool for PostgreSQL that provides support for full, differential, and incremental backups.[91]
pgaudit
pgaudit is a PostgreSQL extension that provides detailed session and/or object audit logging via the standard logging facility provided by PostgreSQL.[92]
wal-e
Wal-e is a backup and restore tool for PostgreSQL that provides support for physical (WAL based) backups, written in Python[93]
A number of companies offer proprietary tools for PostgreSQL. They often consist of a universal core that is adapted for various specific database products. These tools mostly share the administration features with the open source tools but offer improvements in data modeling, importing, exporting or reporting.
Notable users
Notable organizations and products that use PostgreSQL as the primary database include:
In 2009, the social-networking website Myspace used Aster Data Systems's nCluster database for data warehousing, which was built on unmodified PostgreSQL.[94][95]
Geni.com uses PostgreSQL for their main genealogy database.[96]
OpenStreetMap, a collaborative project to create a free editable map of the world.[97]
Afilias, domain registries for .org, .info and others.[98][99]
Disqus, an online discussion and commenting service.[109]
TripAdvisor, travel-information website of mostly user-generated content.[110]
Yandex, a Russian internet company switched its Yandex.Mail service from Oracle to Postgres.[111]
Amazon Redshift, part of AWS, a columnar online analytical processing (OLAP) system based on ParAccel's Postgres modifications.
National Oceanic and Atmospheric Administration's (NOAA) National Weather Service (NWS), Interactive Forecast Preparation System (IFPS), a system that integrates data from the NEXRAD weather radars, surface, and hydrology systems to build detailed localized forecast models.[99][112]
United Kingdom's national weather service, Met Office, has begun swapping Oracle for PostgreSQL in a strategy to deploy more open source technology.[112][113]
WhitePages.com had been using Oracle and MySQL, but when it came to moving its core directories in-house, it turned to PostgreSQL. Because WhitePages.com needs to combine large sets of data from multiple sources, PostgreSQL's ability to load and index data at high rates was a key to its decision to use PostgreSQL.[99]
The Guardian migrated from MongoDB to PostgreSQL in 2018.[116]
Service implementations
Some notable vendors offer PostgreSQL as software as a service:
Heroku, a platform as a service provider, has supported PostgreSQL since the start in 2007.[117] They offer value-add features like full database roll-back (ability to restore a database from any specified time),[118] which is based on WAL-E, open-source software developed by Heroku.[119]
In January 2012, EnterpriseDB released a cloud version of both PostgreSQL and their own proprietary Postgres Plus Advanced Server with automated provisioning for failover, replication, load-balancing, and scaling. It runs on Amazon Web Services.[120] Since 2015, Postgres Advanced Server has been offered as ApsaraDB for PPAS, a relational database as a service on Alibaba Cloud.[121]
VMware has offered vFabric Postgres (also termed vPostgres[122]) for private clouds on VMware vSphere since May 2012.[123] The company announced End of Availability (EOA) of the product in 2014.[124]
In November 2013, Amazon Web Services announced the addition of PostgreSQL to their Relational Database Service offering.[125][126]
In November 2016, Amazon Web Services announced the addition of PostgreSQL compatibility to their cloud-native Amazon Aurora managed database offering.[127]
In May 2017, Microsoft Azure announced Azure Databases for PostgreSQL[128]
In May 2019, Alibaba Cloud announced PolarDB for PostgreSQL.[129]
Jelastic Multicloud Platform as a Service provides container-based PostgreSQL support since 2011. They offer automated asynchronous master-slave replication of PostgreSQL available from marketplace.[130]
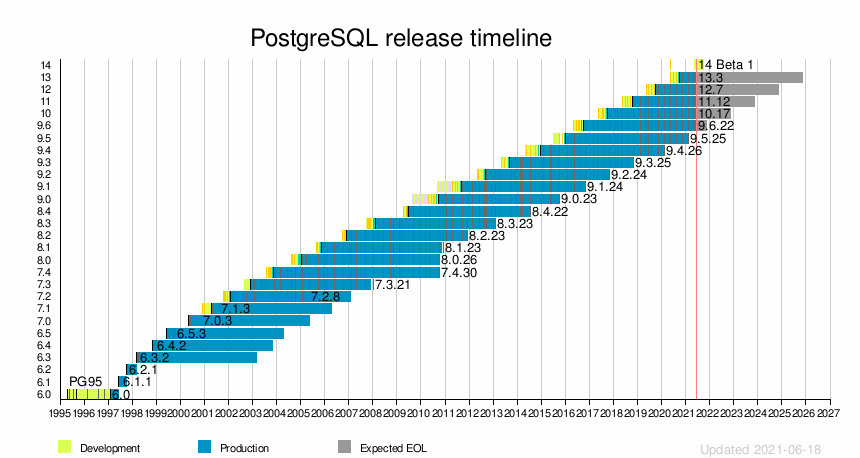
Custom background workers, data checksums, dedicated JSON operators, LATERAL JOIN, faster pg_dump, new pg_isready server monitoring tool, trigger features, view features, writeable foreign tables, materialized views, replication improvements
9.4
2014-12-18
Old version, no longer maintained: 9.4.26
2020-02-13
2020-02-13
JSONB data type, ALTER SYSTEM statement for changing config values, ability to refresh materialized views without blocking reads, dynamic registration/start/stop of background worker processes, Logical Decoding API, GiN index improvements, Linux huge page support, database cache reloading via pg_prewarm, reintroducing Hstore as the column type of choice for document-style data.[143]
9.5
2016-01-07
Old version, no longer maintained: 9.5.25
2021-02-11
2021-02-11
UPSERT, row level security, TABLESAMPLE, CUBE/ROLLUP, GROUPING SETS, and new BRIN index[144]
9.6
2016-09-29
Older version, yet still maintained: 9.6.22
2021-05-13
2021-11-11
Parallel query support, PostgreSQL foreign data wrapper (FDW) improvements with sort/join pushdown, multiple synchronous standbys, faster vacuuming of large table
Increased robustness and performance for partitioning, transactions supported in stored procedures, enhanced abilities for query parallelism, just-in-time (JIT) compiling for expressions[146][147]
12
2019-10-03
Older version, yet still maintained: 12.7
2021-05-13
2024-11-14
Improvements to query performance and space utilization; SQL/JSON path expression support; generated columns; improvements to internationalization, and authentication; new pluggable table storage interface.[148]
13
2020-09-24
Current stable version:13.3
2021-05-13
2025-11-13
Space savings and performance gains from de-duplication of B-tree index entries, improved performance for queries that use aggregates or partitioned tables, better query planning when using extended statistics, parallelized vacuuming of indexes, incremental sorting[149][150]
^ abStonebraker, M.; Rowe, L. A. (May 1986). The design of POSTGRES(PDF). Proc. 1986 ACM SIGMOD Conference on Management of Data. Washington, DC. Retrieved December 17, 2011.
^ ab"Mac OS X packages". The PostgreSQL Global Development Group. Retrieved August 27, 2016.
^"Michael Stonebraker – A.M. Turing Award Winner". amturing.acm.org. Retrieved March 20, 2018. Techniques pioneered in Postgres were widely implemented [..] Stonebraker is the only Turing award winner to have engaged in serial entrepreneurship on anything like this scale, giving him a distinctive perspective on the academic world.
^Stonebraker, M.; Rowe, L. A. The POSTGRES data model(PDF). Proceedings of the 13th International Conference on Very Large Data Bases. Brighton, England: Morgan Kaufmann Publishers. pp. 83–96. ISBN 0-934613-46-X.
^Obe, Regina; Hsu, Leo S. (2012). "10: Replication and External Data". PostgreSQL: Up and Running (1 ed.). Sebastopol, CA: O'Reilly Media, Inc. p. 129. ISBN 978-1-4493-2633-3. Retrieved October 17, 2016. Foreign Data Wrappers (FDW) [...] are mechanisms of querying external datasources. PostgreSQL 9.1 introduced this SQL/MED standards compliant feature.
^O'Doherty, Paul; Asselin, Stephane (2014). "3: VMware Workspace Architecture". VMware Horizon Suite: Building End-User Services. VMware Press Technology. Upper Saddle River, NJ: VMware Press. p. 65. ISBN 978-0-13-347910-2. Retrieved September 19, 2016. In addition to the open source version of PostgreSQL, VMware offers vFabric Postgres, or vPostgres. vPostgres is a PostgreSQL virtual appliance that has been tuned for virtual environments.
Douglas, Korry (August 5, 2005). PostgreSQL (second ed.). Sams. p. 1032. ISBN 0-672-32756-2.
Matthew, Neil; Stones, Richard (April 6, 2005). Beginning Databases with PostgreSQL (second ed.). Apress. p. 664. ISBN 1-59059-478-9. Archived from the original on April 9, 2009. Retrieved April 28, 2009.
Worsley, John C; Drake, Joshua D (January 2002). Practical PostgreSQL. O'Reilly Media. pp. 636. ISBN 1-56592-846-6.
![The World's Most Advanced Open Source Relational Database[1]](http://codedocs.org/uploads/220px-Postgresql_elephant.svg.png)