| Part of a series on |
| Translation |
|---|
 |
| Types |
|
| Theory |
|
| Technologies |
|
| Localization |
|
| Institutional |
|
| Related topics |
|
In computing, internationalization and localization (American) or internationalisation and localisation (BrE), often abbreviated i18n and L10n,[1] are means of adapting computer software to different languages, regional peculiarities and technical requirements of a target locale.[2] Internationalization is the process of designing a software application so that it can be adapted to various languages and regions without engineering changes. Localization is the process of adapting internationalized software for a specific region or language by translating text and adding locale-specific components. Localization (which is potentially performed multiple times, for different locales) uses the infrastructure or flexibility provided by internationalization (which is ideally performed only once before localization, or as an integral part of ongoing development).[3]
The terms are frequently abbreviated to the numeronyms i18n (where 18 stands for the number of letters between the first i and the last n in the word internationalization, a usage coined at Digital Equipment Corporation in the 1970s or 1980s)[4][5] and L10n for localization, due to the length of the words.[1][6] Some writers have the latter acronym capitalized to help distinguish the two.[7]
Some companies, like IBM and Oracle, use the term globalization, g11n, for the combination of internationalization and localization.[8]
Microsoft defines internationalization as a combination of world-readiness and localization. World-readiness is a developer task, which enables a product to be used with multiple scripts and cultures (globalization) and separating user interface resources in a localizable format (localizability, abbreviated to L12y).[9][10]
Hewlett-Packard and HP-UX created a system called "National Language Support" or "Native Language Support" (NLS) to produce localizable software.[2]
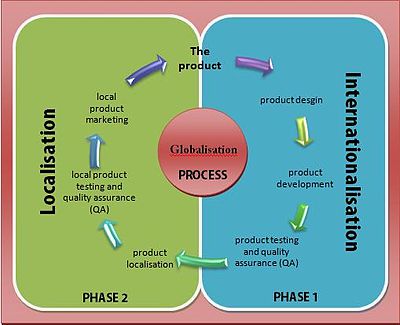
According to Software without frontiers, the design aspects to consider when internationalizing a product are "data encoding, data and documentation, software construction, hardware device support, user interaction"; while the key design areas to consider when making a fully internationalized product from scratch are "user interaction, algorithm design and data formats, software services, documentation".[2]
Translation is typically the most time-consuming component of language localization.[2] This may involve:
Computer software can encounter differences above and beyond straightforward translation of words and phrases, because computer programs can generate content dynamically. These differences may need to be taken into account by the internationalization process in preparation for translation. Many of these differences are so regular that a conversion between languages can be easily automated. The Common Locale Data Repository by Unicode provides a collection of such differences. Its data is used by major operating systems, including Microsoft Windows, macOS and Debian, and by major Internet companies or projects such as Google and the Wikimedia Foundation. Examples of such differences include:
Different countries have different economic conventions, including variations in:
In particular, the United States and Europe differ in most of these cases. Other areas often follow one of these.
Specific third-party services, such as online maps, weather reports, or payment service providers, might not be available worldwide from the same carriers, or at all.
Time zones vary across the world, and this must be taken into account if a product originally only interacted with people in a single time zone. For internationalization, UTC is often used internally and then converted into a local time zone for display purposes.
Different countries have different legal requirements, meaning for example:
Localization also may take into account differences in culture, such as:
In order to internationalize a product, it is important to look at a variety of markets that the product will foreseeably enter.[2] Details such as field length for street addresses, unique format for the address, ability to make the postal code field optional to address countries that do not have postal codes or the state field for countries that do not have states, plus the introduction of new registration flows that adhere to local laws are just some of the examples that make internationalization a complex project.[7][16] A broader approach takes into account cultural factors regarding for example the adaptation of the business process logic or the inclusion of individual cultural (behavioral) aspects.[2][17]
Already in the 1990s, companies such as Bull used machine translation (Systran) in large scale, for all their translation activity: human translators handled pre-editing (making the input machine-readable) and post-editing.[2]
Both in re-engineering an existing software or designing a new internationalized software, the first step of internationalization is to split each potentially locale-dependent part (whether code, text or data) into a separate module.[2] Each module can then either rely on a standard library/dependency or be independently replaced as needed for each locale.
The current prevailing practice is for applications to place text in resource strings which are loaded during program execution as needed.[2] These strings, stored in resource files, are relatively easy to translate. Programs are often built to reference resource libraries depending on the selected locale data.
The storage for translatable and translated strings is sometimes called a message catalog[2] as the strings are called messages. The catalog generally comprises a set of files in a specific localization format and a standard library to handle said format. One software library and format that aids this is gettext.
Thus to get an application to support multiple languages one would design the application to select the relevant language resource file at runtime. The code required to manage data entry verification and many other locale-sensitive data types also must support differing locale requirements. Modern development systems and operating systems include sophisticated libraries for international support of these types, see also Standard locale data above.
Many localization issues (e.g. writing direction, text sorting) require more profound changes in the software than text translation. For example, OpenOffice.org achieves this with compilation switches.
A globalization method includes, after planning, three implementation steps: internationalization, localization and quality assurance.[2]
To some degree (e.g. for quality assurance), development teams include someone who handles the basic/central stages of the process which then enable all the others.[2] Such persons typically understand foreign languages and cultures and have some technical background. Specialized technical writers are required to construct a culturally appropriate syntax for potentially complicated concepts, coupled with engineering resources to deploy and test the localization elements.
Once properly internationalized, software can rely on more decentralized models for localization: free and open source software usually rely on self-localization by end-users and volunteers, sometimes organized in teams.[18] The KDE3 project, for example, has been translated into over 100 languages;[19]MediaWiki in 270 languages, of which 100 mostly complete as of 2016[update].[20]
When translating existing text to other languages, it is difficult to maintain the parallel versions of texts throughout the life of the product.[21] For instance, if a message displayed to the user is modified, all of the translated versions must be changed.
In a commercial setting, the benefit from localization is access to more markets. In the early 1980s, Lotus 1-2-3 took two years to separate program code and text and lost the market lead in Europe over Microsoft Multiplan.[2] MicroPro found that using an Austrian translator for the West German market caused its WordStar documentation to, an executive said, not "have the tone it should have had".[22]
However, there are considerable costs involved, which go far beyond engineering. Further, business operations must adapt to manage the production, storage and distribution of multiple discrete localized products, which are often being sold in completely different currencies, regulatory environments and tax regimes.
Finally, sales, marketing and technical support must also facilitate their own operations in the new languages, in order to support customers for the localized products. Particularly for relatively small language populations, it may never be economically viable to offer a localized product. Even where large language populations could justify localization for a given product, and a product's internal structure already permits localization, a given software developer or publisher may lack the size and sophistication to manage the ancillary functions associated with operating in multiple locales.
In a nutshell, localization revolves around combining language and technology to produce a product that can cross cultural and language barriers. No more, no less.
Two long words appear all the time when we discuss support of native language in programs, and these words have a precise meaning, worth being explained here, once and for all in this document. The words are internationalization and localization. Many people, tired of writing these long words over and over again, took the habit of writing i18n and l10n instead, quoting the first and last letter of each word, and replacing the run of intermediate letters by a number merely telling how many such letters there are.
The capital L in L10n helps to distinguish it from the lowercase i in i18n.
By: Wikipedia.org
Edited: 2021-06-18 19:11:07
Source: Wikipedia.org