 Stata 17 on Windows | |
| Original author(s) | William Gould[1] |
|---|---|
| Developer(s) | StataCorp |
| Initial release | 1985 |
| Stable release | 17.0
/ April 20, 2021 |
| Written in | C |
| Operating system | Windows, macOS, Linux |
| Type | Statistical analysis |
| License | Proprietary |
| Website | www |
Stata is a general-purpose statistical software package developed by StataCorp for data manipulation, visualization, statistics, and automated reporting. It is used by researchers in many fields, including economics, sociology, political science, biomedicine, and epidemiology.[2] StataCorp personnel pronounce Stata /ˈsteɪtə/.[3]
Stata was initially developed by Computing Resource Center in California and the first version was released in 1985.[4] In 1993, the company moved to College Station, TX and was renamed Stata Corporation, now known as StataCorp.[1] A major release in 2003 included a new graphics system and dialog boxes for all commands.[4] Since then, a new version has been released once every two years.[5] The current version is Stata 17, released in April 2021.[6]
Stata has always emphasized a command-line interface, which facilitates replicable analyses. Starting with version 8.0, however, Stata has included a graphical user interface based on Qt framework which uses menus and dialog boxes to give access to nearly all built-in commands. This generates code which is always displayed, easing the transition to the command line interface and more flexible scripting language. The dataset can be viewed or edited in spreadsheet format. From version 11 on, other commands can be executed while the data browser or editor is opened.
Until the release of version 16,[7] Stata could only open a single dataset at any one time. Stata holds datasets in (random-access or virtual) memory, which limits its use with extremely large datasets. This is mitigated to some extent by efficient internal storage, as there are integer storage types which occupy only one or two bytes rather than four, and single-precision (4 bytes) rather than double-precision (8 bytes) is the default for floating-point numbers.
The dataset is always rectangular in format, that is, all variables hold the same number of observations (in more mathematical terms, all vectors have the same length, although some entries may be missing values).
Stata can import data in a variety of formats. This includes ASCII data formats (such as CSV or databank formats) and spreadsheet formats (including various Excel formats).
Stata's proprietary file formats have changed over time, although not every Stata release includes a new dataset format. Every version of Stata can read all older dataset formats, and can write both the current and most recent previous dataset format, using the saveold command.[8] Thus, the current Stata release can always open datasets that were created with older versions, but older versions cannot read newer format datasets.
Stata can read and write SAS XPORT format datasets natively, using the fdause and fdasave commands.
Some other econometric applications, including gretl, can directly import Stata file formats.
Stata allows user-written commands, distributed as so-called ado-files, to be straightforwardly downloaded from the internet which are then indistinguishable to the user from the built-in commands. In this respect, Stata combines the extensibility more often associated with open-source packages with features usually associated with commercial packages such as software verification, technical support and professional documentation. Some user-written commands have later been adopted by StataCorp to become part of a subsequent official release after appropriate checking, certification, and documentation.
The development of Stata began in 1984, initially by William (Bill) Gould and later by Sean Becketti. The software was originally intended to compete with statistical programs for personal computers such as SYSTAT and MicroTSP.[4] Stata was written, then as now, in the C programming language, initially for PCs running the DOS operating system. The first version was released in 1985 with 44 commands.[4]
| append | dir | infile | plot | spool |
| beep | do | input | query | summarize |
| by | drop | label | regress | tabulate |
| capture | erase | list | rename | test |
| confirm | exit | macro | replace | type |
| convert | expand | merge | run | use |
| correlate | format | modify | save | |
| count | generate | more | set | |
| describe | help | outfile | sort |
There have been 17 major releases of Stata between 1985 and 2021, and additional code and documentation updates between major releases.[5] In its early years, extra sets of Stata programs were sometimes sold as "kits" or distributed as Support Disks. With the release of Stata 6 in 1999, updates began to be delivered to users via the web.[4]
Hundreds of commands have been added to Stata in its 36-year history.[9][10] Certain developments have proved to be particularly important and continue to shape the user experience today, including extensibility, platform independence, and the active user community.[4]
program command was implemented in Stata 1.2, giving users the ability to add their own commands.[4][11] ado-files followed in Stata 2.1, allowing a user-written program to be automatically loaded into memory. Many user-written ado-files are submitted to the Statistical Software Components Archive (SSC) maintained by Christopher (Kit) Baum and hosted by Boston College. StataCorp added an ssc command to allow community-contributed programs to be added directly within Stata.[12]| Version | Release date | Select new or enhanced features |
|---|---|---|
| 1.0 | January 1985 |
|
| 1.1 | February 1985 |
|
| 1.2 | May 1985 |
|
| 1.3 | August 1985 |
|
| 1.4 | August 1986 |
|
| 1.5 | February 1987 |
|
| 2.0 | June 1988 |
|
| 2.1 | September 1990 |
|
| 3.0 | March 1992 |
|
| 3.1 | August 1993 |
|
| 4.0 | January 1995 |
|
| 5.0 | October 1996 |
|
| 6.0 | January 1999 |
|
| 7.0 | December 2000 |
|
| 8.0 | January 2003 |
|
| 8.1 | July 2003 |
|
| 8.2 | October 2003 |
|
| 9.0 | April 2005 |
|
| 9.1 | September 2005 | |
| 9.2 | April 2006 | |
| 10.0 | June 2007 |
|
| 10.1 | August 2008 | |
| 11.0 | July 2009 |
|
| 11.1 | June 2010 | |
| 11.2 | March 2011 | |
| 12.0 | July 2011 |
|
| 12.1 | January 2012 | |
| 13.0 | June 2013 |
|
| 13.1 | October 2013 | |
| 14.0 | April 2015 |
|
| 14.1 | October 2015 | |
| 14.2 | September 2016 | |
| 15.0 | June 2017 |
|
| 15.1 | November 2017 | |
| 16.0 | June 2019 |
|
| 16.1 | February 2020 | |
| 17.0 | April 2021 |
|
There are four builds of Stata:[13]
Stata/MP can store 10 to 20 billion observations and up to 120,000 variables. Stata/SE and Stata/BE can each store up to 2.14 billion observations and handle 32,767 variables and 2,048 variables respectively. The maximum number of independent variables in a model is 65,532 variables in Stata/MP, 10,998 variables in Stata/SE, and 798 variables in Stata/BE.[13]
The pricing and licensing of Stata depends on its intended use: business, government/nonprofit, education, or student. Single user licenses are either renewable annually or perpetual. Other license types include a single license for use by concurrent users, a site license, volume single user for bulk pricing, or a student lab.[14]
User Group meetings are held annually in the United States (the Stata Conference), the UK, Germany, and Italy, and less frequently in several other countries. Only the annual Stata Conference held in the United States is hosted by StataCorp LP. Local Stata distributors host User Group meetings in their own countries, however, Stata developers frequently travel to and present at these meetings. Established under the Societies Act on 10 May 2008, Singapore Stata Users Group is the world's first government-approved users group (Registration No: 2048/2008; Unique Entity No: T08SS0091A). Its slogan is "Shaping Data Meaningfully". As a non-profit organisation, StataUGS does not organise regular meetings but provides programming and statistical advice to users in Singapore through informal means. The active members of StataUGS are mostly engaged in biomedical research.
The following set of commands revolve around simple data management.[15]
sysuse auto // Open the included auto dataset
browse // Browse the dataset (opens the Data Editor window)
describe // Describes the dataset and associated variables
summarize // Summary information about numerical variables
codebook make foreign // Summary information about the make (string) and foreign (numeric) variables
browse if missing(rep78) // Browse only observations with missing data for variable rep78
list make if missing(rep78) // List makes of the cars with missing data for variable rep78
The next set of commands move onto descriptive statistics.
summarize price, detail // Detailed summary statistics for variable price
tabulate foreign // One-way frequency table for variable foreign
tabulate rep78 foreign, row // Two-way frequency table for variables rep78 and foreign
summarize mpg if foreign == 1 // Summary information about mpg if the car is foreign (the "==" sign tests for equality)
by foreign, sort: summarize mpg // As above, but using the "by" prefix.
tabulate foreign, summarize(mpg) // As above, but using the tabulate command.
A simple hypothesis test:
ttest mpg, by(foreign) // T-test for difference in means for domestic vs. foreign cars
Graphing data:
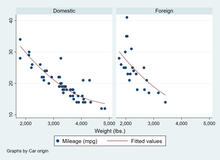
twoway (scatter mpg weight) // Scatter plot showing relationship between mpg and weight
twoway (scatter mpg weight), by(foreign, total) // Three graphs for domestic, foreign, and all cars
Linear regression:
generate wtsq = weight^2 // Create a new variable for weight squared
regress mpg weight wtsq foreign, vce(robust) // Linear regression of mpg on weight, wtsq, and foreign
predict mpghat // Create a new variable contained the predicted values of mpg
twoway (scatter mpg weight) (line mpghat weight, sort), by(foreign) // Graph data and fitted line
By: Wikipedia.org
Edited: 2021-06-18 18:19:39
Source: Wikipedia.org