Distributed Data Management Architecture (DDM) is IBM's open, published software architecture for creating, managing and accessing data on a remote computer. DDM was initially designed to support record-oriented files; it was extended to support hierarchical directories, stream-oriented files, queues, and system command processing; it was further extended to be the base of IBM's Distributed Relational Database Architecture (DRDA); and finally, it was extended to support data description and conversion. Defined in the period from 1980 to 1993, DDM specifies necessary components, messages, and protocols, all based on the principles of object-orientation. DDM is not, in itself, a piece of software; the implementation of DDM takes the form of client and server products. As an open architecture, products can implement subsets of DDM architecture and products can extend DDM to meet additional requirements. Taken together, DDM products implement a distributed file system.

The designers of distributed applications must determine the best placement of the application's programs and data in terms of the quantity and frequency of data to be transmitted, along with data management, security, and timeliness considerations. There are three client–server models for the design of distributed applications:
The DDM architecture was initially designed to support the fat client model of distributed applications; it also supports whole-file transfers.
The DDM architecture provides distributed applications with the following benefits:[1]
DDM architecture is a set of specifications for messages and protocols that enable data distributed throughout a network of computers to be managed and accessed. [2]
IBM's Systems Network Architecture (SNA) was initially designed to enable the hierarchical connection of workstations to IBM mainframe computers. The communication networks available at the time were rigidly designed in terms of fixed connections between a mainframe and its suite of workstations, which were under the complete software control of the mainframe computer. Other communications between mainframes was also in terms of fixed connections used by software defined for specific purposes. As communication networks became more flexible and dynamic, generic peer-to-peer communications were desirable, in which a program on one computer could initiate and interact with a program on a different computer.
When IBM's SNA Advanced Program to Program Communications (APPC) architecture was defined in the early 1980s, it was also apparent that APPC could be used to provide operating system services on remote computers. An SNA workgroup pursued this idea and outlined several possible distributed services, such as file services, printer services, and system console services, but was unable to initiate product development. APPC software was not yet available on mainframes and, more basically, mainframes were still viewed primarily as stand-alone systems. As a result, work on distributed services was suspended by the SNA work group.
Members of the SNA work group from IBM's Rochester, Minnesota development laboratory were convinced that a business case existed for distributed services among the mid-range computer systems produced in Rochester. A primitive form of distributed file services, called Distributed Data File Facility (DDFF) had been implemented to connect the IBM System/3, IBM System/34, and IBM System/36 minicomputers. Further, the IBM System/36 and the IBM System/38 computers were being sold to customers in multiples and there was a clear need to enable, for example, the headquarters computers of a company to interact with the computers in its various warehouses. APPC was implemented on these systems and used by various customer applications. The idea of distributed operating system services was then revived as the Golden Gate project and an attempt made to justify its development. This attempt also failed; the whole idea of distributed services was too new for IBM product planners to be able to quantify the value of software that interconnected heterogeneous computers.
However, one Golden Gate planner, John Bondy, remained convinced and persuaded management to create a department outside of the normal control of the Rochester laboratory so that there would be no immediate need for a predefined business case. Further, he narrowed its mission to include only support for Distributed Data Management (DDM), in particular, support for record-oriented files. He then convinced an experienced software architect, Richard A. Demers, to join him in the tasks of defining DDM architecture and selling the idea of DDM to the IBM system houses.
The first year of this effort was largely fruitless as the IBM system houses continued to demand up-front business cases and as they insisted on message formats isomorphic to the control block interfaces of their local file systems. Further, as Personal Computers began to be used as terminals attached to mainframe computers, it was argued that simply enhancing the 3270 data stream would enable PCs to access mainframe data.
During this period, Demers designed an architectural model of DDM clients and servers, of their components, and of interactions between communicating computers. Further, he defined a generic format for DDM messages based on the principles of object-orientation as pioneered by the Smalltalk programming language and by the IBM System/38. This model made it clear how DDM products could be implemented on various systems. See How DDM works.
In 1982, the System/36 planners became convinced there was a sufficient market for DDM record-oriented file services.[3]
The generic format of DDM messages had already been designed, but what specific messages should be defined? The System/36 file system had been defined to meet the record-oriented needs of third generation programming languages (3GLs), such as Fortran, COBOL, PL/I, and IBM RPG, and so had the System/38 file system and the Virtual Storage Access Method (VSAM) file system of the IBM mainframe computers. And yet, their actual facilities and interfaces varied considerably, so what facilities and interfaces should DDM architecture support? See record-oriented files.
The initial work on DDM by the Golden Gate project had followed the lead of the File Transfer Access and Management (FTAM) international standard for distributed files, but it was very abstract and difficult to map to local file services. In fact, this had been one of the barriers to acceptance by the IBM system houses. Kenneth Lawrence, the system architect responsible for System/36 file services, argued that it would be better to define messages that at least one IBM system could easily implement and then let other systems request whatever changes they needed. Naturally, he argued for support of System/36 requirements. After a year of failure to sell the idea of DDM to other IBM system houses, Lawrence's arguments prevailed.
Richard Sanders joined the DDM architecture team and worked with Lawrence and Demers to define the specific messages needed for System/36 DDM. Progress in the definition of DDM encouraged System/38 to also participate. This broadened the scope of DDM record-file support to meet many of the requirements of the System/38's advanced file system.
Files exist in a context provided by an operating system that provides services for organizing files, for sharing them with concurrent users and for securing them from unwarranted access. In level 1 of DDM, access to remote file directories was not supported beyond the transmission of the fully qualified name of the file to be used. Security and sharing, however, were required. Sanders did the design work in these areas. Sanders also defined specific protocols regarding the use of communication facilities, which were incorporated in a component called the DDM Conversational Communications Manager. Initially implemented using APPC, it was later implemented using TCP/IP.
With the completion of the System/36 DDM product, Lawrence worked with programmers from the IBM Hursley Park, UK laboratory to adapt much of the System/36 DDM server programming for use in the IBM Customer Information Control System (CICS) transaction processing environment, thereby making CICS a DDM server for both the MVS and VSE mainframe operating systems.[4] Lawrence also worked with programmers from the IBM Cary, North Carolina laboratory to implement a DDM record-oriented client for IBM PC DOS.
Level 1 of DDM Architecture was formally published in 1986. At the time of this announcement, IBM presented an Outstanding Technical Achievement Award to Kenneth Lawrence, an Outstanding Contribution Award to Richard Sanders, and an Outstanding Innovation Award to Richard Demers.
With the increasing importance of the IBM PC and the Unix operating system in network environments, DDM support was also needed for the hierarchical directories and stream-oriented files of the IBM Personal Computer running IBM PC DOS and the IBM RS/6000 running IBM AIX (IBM's version of Unix). See Stream-oriented files.
DDM Architecture Level 2 was published in 1988. Jan Fisher and Sunil Gaitonde did most of the architecture work on DDM support for directories and stream files.
In 1986, IBM marketed four different relational database (RDB) products, each built for a specific IBM operating system. Scientists at IBM's Almaden Research Laboratory had developed System/R*, a prototype of a distributed RDB and they felt it was now time to turn it into marketable products. However, System/R* was based on System/R, a research prototype of a RDB, and could not be easily added to the IBM RDB products. See[6] for a discussion of RDBs in a distributed processing environment.
Roger Reinsch from the IBM Santa Theresa Programming Center lead a cross-product team to define a Distributed Relational Database Architecture (DRDA). He enlisted:
In 1990, DDM Architecture Level 3 and DRDA[7] were published at the same time. Both DDM and DRDA were designated as strategic components of IBM's Systems Application Architecture (SAA). DRDA was implemented by all four of the IBM RDB products and by other vendors.
Awards were given to key participants in the design of DRDA. Richard Sanders received an Outstanding Contribution Award and Roger Reinsch and Richard Demers received Outstanding Innovation Awards.
The Distributed File Management (DFM)[8] project was initiated to add DDM services to IBM's MVS operating system to enable programs on remote computers to create, manage, and access VSAM files. John Hufferd, the manager of the DFM project looked to the DDM Architecture team for a means of converting the data fields in records as they flowed between systems. Richard Demers took the lead on this issue, aided by Koichi Yamaguchi from the DFM project. See Data description and conversion.
The following additional services were defined by Richard Sanders, Jan Fisher and Sunil Gaitonde in DDM architecture at Level 4:
DDM architecture level 4 was published in 1992.
Architecture work on DDM level 5 consisted of support for
Jan Fisher was the architect responsible for DDM level 5, which was published by the Open Group, rather than IBM. Shortly thereafter, the IBM DDM architecture group was disbanded.
DDM architecture is a formally defined and highly structured set of specifications. This section introduces key technical concepts that underlie DDM.[2]
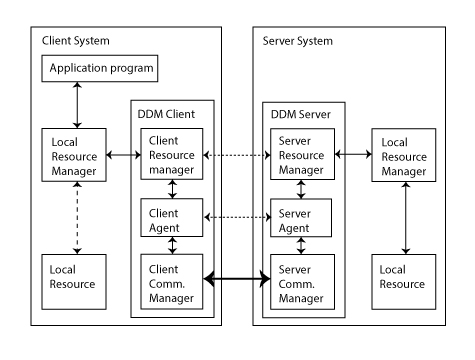
DDM architecture defines a client/server protocol; that is, a client requests services from a server which interacts with its local resources to perform the requested service, the results of which, data and status indicators, are returned to the client. The above diagram illustrates the roles of DDM clients and servers in relation to local resources. (The common terminology of clients and servers is used here, but in DDM architecture, a client is called a Source Server and a Server is called a Target Server.)
DDM architecture is object-oriented. All entities defined by DDM are objects defined by self-defining Class objects. The messages, replies and data that flow between systems are serialized objects. Each object specifies its length, identifies its class by means of a DDM codepoint, and contains data as defined by its class. Further, its class specifies the commands that can be sent to its instances when an object resides in a DDM client or server, thereby encapsulating the object by a limited set of operations.
Structurally, DDM architecture consists of hierarchical levels of objects, each level manifesting emergent properties at increasingly higher levels.
While DDM architecture is object-oriented, the DDM products were implemented using the languages and methods typical of their host systems. A Smalltalk version of DDM was developed for the IBM PC by Object Technology International, with appropriate Smalltalk classes automatically created from the DDM Reference Manual.
DDM is an open architecture. DDM products can implement subsets of DDM architecture; they can also create their own extensions. [11]
The DDM 'Exchange Server Attributes' command is the first command sent when a client is connected with a server. It identifies the client and specifies the managers the client requires and the level of DDM architecture at which support is required. The server responds by identifying itself and specifying at what level it supports the requested managers. A general rule is that a product that supports Level X of a DDM manager must also support Level X-1 so that new server products connect with older client products.
Subsets of DDM can be implemented to meet varying product requirements:
When a DDM client is connected to a known DDM server, such as a System/38 client to a System/38 server, DDM architecture can also be extended by adding
Such extensions can be defined within DDM's object-oriented framework so that existing DDM message handling facilities can be used.
In a purely object-oriented implementation of DDM, clients and servers and all of their contained managers and objects exist in a memory heap, with pointers (memory addresses) used to interconnect them. For example, a command object points to each of its parameter objects. But a command cannot be transmitted from a client to a server in this way; an isomorphic copy of the command must be created as a single, contiguous string of bits. In the heap, a command consists of the size of the command in the heap, a pointer to the command's class, and pointers to each of the command's parameter objects. Linearized, the command consists of the total length of the linearized command, a code point identifying the command's class, and each of its linearized parameter objects. DDM architecture assigns unique code points to each class of object. This straightforward technique is used for all objects transmitted between client's and servers, including commands, records, and reply messages.
All of these linearized objects are put into envelopes that enable the client and server agents to coordinate their processing. In DDM architecture, these envelopes are called Data Stream Structures (DSS). Commands are put into a Request DSS (RQSDSS), replies are put into a Reply DSS (RPYDSS), and other objects are put into an Object DSS (OBJDSS). There can be only one command in a RQSDSS and only one reply in RPYDSS, but many objects, such as records, can be put into an OBJDSS. Further many OBJDSSes can be chained to a RQSDSS or a PRYDSS to accommodate as many objects as necessary. A DSS consists of the total length of the DSS, a flag byte identifying the type of DSS, a request identifier, and the linearized objects in the DSS. The request identifier ties an RQSDSS with subsequent OBJDSSes from the client, such as the records to be loaded into a file by the Load File command. The request identifier also ties the RQSDSS from the client with a RPYDSS or the OBJDSSes from the server to the client.
The DDM Reference Manual[12][13] consists of named Menu, Help, and Class objects. The subclasses of DDM class Class are described by variables that specify
These objects can contain references to other named objects in text and specifications, thereby creating hypertext linkages among the pages of the DDM Reference Manual. Menu and Help pages form an integrated tutorial about DDM. The paper version of the DDM Reference Manual Level 3 is bulky, at over 1400 pages, and somewhat awkward to use, but an interactive version was also built using internal IBM communication facilities. Given the relatively slow speed of those communication facilities, it was primarily of use within the IBM Rochester laboratory.
In addition to the DDM Reference Manual, a General Information[1] document provide's executive level information about DDM, and a Programmer's Guide[11] summarizes DDM concepts for programmers implementing clients and servers.
Three general file models are defined by DDM architecture: record-oriented files, stream-oriented files and hierarchical directories.
The following services are provided by DDM architecture for managing remote files:
Record-oriented files were designed to meet the data input, output, and storage requirements of third generation (3GL) programming languages, such as Fortran, Cobol, PL/I, and RPG. Rather than have each language provide its own support for these capabilities, they were incorporated into services provided by operating systems.
A record is a series of related data fields, such as the name, address, identification number and salary of a single employee, in which each field is encoded and mapped to a contiguous string of bytes. Early computers had limited input and output capabilities, typically in the form of stacks of 80 column punched cards or in the form of paper or magnetic tapes. Application records, such as employee data records, were sequentially read or written a record at a time and processed in batches. When direct access storage devices became available, programming languages added ways for programs to randomly access records one at a time, such as access by the values of key fields or by the position of a record in a file. All of the records in a file can be of the same format (as in a payroll file) or of varying formats (as in an event log). Some files are read-only in that their records, once written to the file, can only be read, while other files allow their records to be updated.
The DDM record-oriented file models consist of file attributes, such as its creation date, the date of last update, the size of its records, and slots in which records can be stored. The records can be of either fixed or varying length, depending on the media used to store the file's records. DDM defines four kinds of record-oriented files:
DDM architecture also defines a variety of access methods for working with record-oriented files in various ways. An access method is an instance of the use of a file created by means of an OPEN command that connects itself to the file after determining if the client is authorized to use it. The access method is disconnected from a file by means of a CLOSE command.
An access method keeps track of the record being currently processed by means of a cursor. Using various SET commands, the cursor can be made to point to the beginning or end of the file, to the next or previous sequential record of the file, to the record with a specific key value, or to the next or previous record as ordered by their keys.
Multiple instances of access methods can be opened on a file at the same time, each serving a single client. If a file is opened for update access, conflicts can occur when the same record is being accessed by multiple clients. To prevent such conflicts, a lock can be obtained on an entire file. Also, if a file is opened for update a lock is obtained on a record by the first client to read it and released when that client updates it. All other clients must wait for the lock's release.
Stream-oriented files consist of a single sequence of bytes on which programs can map application data however they want. Stream files are the primary file model supported by Unix and Unix-like operating systems and by Windows. DDM defines a single stream file model and a single stream access method.
The DDM stream file model consists of file attributes, such as its creation date and the size of the stream and a continuous stream of bytes. The stream can be accessed by means of the Stream Access Method. Application programs write data onto portions of the stream, even if that data consists of records. They keep track of the location of data items in the stream in any way they want. For example, the data stream of document files is defined by a text processing program such as Microsoft Word and that of a spreadsheet file by a program such as Microsoft Excel.
A Stream access method is an instance of use of a stream file by a single client. A cursor keeps track of the position of the current byte of the sub-stream in use by the client. Using various SET commands, the cursor can be made to point to the beginning or end of the file, to any specific position in the file, or to any positive or negative offset from the current position.
Multiple instances of the Stream access method can be opened on a file at the same time, each serving a single client. If a file is opened for "update" access, conflicts can occur when the same sub-stream is being accessed by multiple clients. To prevent such conflicts, a lock can be obtained on an entire file. Also, if a file is opened for update a lock is obtained on a sub-stream by the first client to "read" it and released when that client "updates" it. All other clients must wait for the lock's release.
Hierarchical directories are files whose records each associate a name with a location. A hierarchy occurs when a directory record identifies the name and location of another directory. Using DDM client and server products, a program can create, delete and rename directories in a remote computer. They can also list and change the file attributes of remote directories. The records in a directory can be sequentially read by using the DDM Directory Access Method. The files identified by directory records can be renamed, copied, and moved to a different directory.
Queues are a communication mechanism that enables generally short term communication among programs by means of records. A DDM queue resides in a single system, but it can be accessed by programs on multiple systems. There are three subclasses of DDM queues that can be created on a target system by means of distinct creation commands:
The DDM queue model consists of queue attributes, such as its creation date, the number of records the queue can contain, and the length of the records. The records in a queue can be either fixed or varying length.
Unlike the DDM file models, it is not necessary to open an access method on a queue. Programs can add records to a queue and receive records from a queue as determined by the class of the queue. Programs can also clear records from a queue, stop operations on a queue, list the attributes of a queue, and change the attributes of a queue. Programs can also lock a queue or individual records in a queue to inhibit contention from other programs. All other clients must wait for the lock's release.
A relational database (RDB) is an implementation of the Structured Query Language (SQL) that supports the creation, management, querying, updating, indexing and interrelationships of tables of data. An interactive user or program can issue SQL statements to a RDB and receive tables of data and status indicators in reply. However, SQL statements can also be compiled and stored in the RDB as packages and then invoked by package name. This is important for the efficient operation of application programs that issue complex, high-frequency queries. It is especially important when the tables to be accessed are located in remote systems.
The Distributed Relational Database Architecture (DRDA) fits nicely into the overall DDM framework, as discussed in Object-Orientation. (However, DDM can also be viewed as a component architecture of DRDA since other specifications are also required [2]). The DDM manager-level objects supporting DRDA are named RDB (for relational database) and SQLAM (for SQL Application Manager).
Transparency is a key objective of DDM architecture. Without recompilation, it should be possible to redirect existing application programs to the data management services of a remote computer. For files, this was largely accomplished by DDM clients at the interface/functional level, but what about the data fields in a record? Complete transparency requires that client application programs be able to write and read fields as encoded by their local data management system, regardless of how any remote server encodes them, and that implies automatic data conversions.
For example, IBM mainframe computers encode floating point numbers in hexadecimal format and character data in EBCDIC, while IBM Personal computers encode them in IEEE format and ASCII. Further complexity arose because of the ways in which various programming language compilers map record fields onto strings of bits, bytes, and words in memory. Transparent conversion of a record requires detailed descriptions of both the client view and the server view of a record. Given these descriptions, the fields of the client and server views can be matched, by field name, and appropriate conversions can be performed.
The key issue is obtaining sufficiently detailed record descriptions, but record descriptions are generally specified abstractly in application programs by declaration statements defined by the programming language, with the language compiler handling encoding and mapping details. In a distributed processing environment, what is needed is a single, standardized way of describing records that is independent of all programming languages, one that can describe the wide variety of fixed and varying length record formats found in existing files.
The result was the definition of a comprehensive Data Description and Conversion architecture (DD&C),[14] based on a new, specialized programming language, A Data Language (ADL),[15] for describing client and server views of data records and for specifying conversions. Compiled ADL programs can then be called by a server to perform necessary conversions as records flowed to or from the server.
DD&C architecture went further and defined a means by which programming language declaration statements can be automatically converted to and from ADL, and thus from one programming language to another. This capability was never implemented because of its complexity and cost. However, an ADL compiler was created and ADL programs are called, when available, to perform conversions by DFM and by the IBM 4680 Store System.[16] However, it is necessary for application programmers to manually write the ADL programs.
The following IBM products implemented various subsets of DDM architecture:
For a complete list of the products that have implemented DRDA, see the Open Source DRDA Product Identifier Table.
CICS DDM is no longer available from IBM and support was discontinued, as of December 31, 2003. CICS DDM is no longer available in CICS TS from Version 5.2 onwards.
Support for CICS Distributed Data Management (DDM) is stabilized in CICS TS for VSE/ESA V1.1.1. In a future release of CICS TS for z/VSE, IBM intends to discontinue support for CICS DDM.
CICS Distributed Data Management (CICS/DDM) is not supported with CICS TS for z/VSE V2.1.
By: Wikipedia.org
Edited: 2021-06-18 19:28:10
Source: Wikipedia.org