| Developer(s) | SAP SE |
|---|---|
| Initial release | 2010 |
| Stable release | 2.0 SPS05[1] (June 26, 2020) [±] |
| Written in | C, C++ |
| Operating system | Linux |
| Available in | English |
| Type | Multi-model database |
| License | Proprietary commercial software |
| Website | www |
SAP HANA (high-performance analytic appliance) is an in-memory, column-oriented, relational database management system developed and marketed by SAP SE.[2][3] Its primary function as the software running a database server is to store and retrieve data as requested by the applications. In addition, it performs advanced analytics (predictive analytics, spatial data processing, text analytics, text search, streaming analytics, graph data processing) and includes extract, transform, load (ETL) capabilities as well as an application server.
During the early development of SAP HANA, a number of technologies were developed or acquired by SAP SE. These included TREX search engine (in-memory column-oriented search engine), P*TIME (in-memory online transaction processing (OLTP) Platform acquired by SAP in 2005), and MaxDB with its in-memory liveCache engine.[4][5]
The first major demonstration of the platform was in 2008: teams from SAP SE, the Hasso Plattner Institute and Stanford University demonstrated an application architecture for real-time analytics and aggregation called HYRISE.[6] Former SAP SE executive, Vishal Sikka, mentioned this architecture as "Hasso's New Architecture".[7] Before the name "HANA" stabilized, people referred to this product as "New Database".[8] The software was previously called "SAP High-Performance Analytic Appliance".[9]
A first research paper on HYRISE was published in November 2010.[10] The research engine is later released open source in 2013,[11] and was reengineered in 2016 to become HYRISE2 in 2017.[12]
The first product shipped in late November 2010.[5][13] By mid-2011, the technology had attracted interest but more experienced business customers considered it to be "in early days".[14] HANA support for SAP NetWeaver Business Warehouse was announced in September 2011 for availability by November.[15]
In 2012, SAP promoted aspects of cloud computing.[16] In October 2012, SAP announced a platform as a service offering called the SAP HANA Cloud Platform[17][18] and a variant called SAP HANA One that used a smaller amount of memory.[19][20]
In May 2013, a managed private cloud offering called the HANA Enterprise Cloud service was announced.[21][22]
In May 2013, Business Suite on HANA became available, enabling customers to run SAP Enterprise Resource Planning functions on the HANA platform.[23][24]
S/4HANA, released in 2015, written specifically for the HANA platform, combines functionality for ERP, CRM, SRM and others into a single HANA system.[25] S/4HANA is intended to be a simplified business suite, replacing earlier generation ERP systems.[26] While it is likely that SAP will focus its innovations on S/4HANA, some customers using non-HANA systems have raised concerns of being locked into SAP products. Since S/4HANA requires an SAP HANA system to run, customers running SAP business suite applications on hardware not certified by SAP would need to migrate to a SAP-certified HANA database should they choose the features offered by S/4HANA.[27]
Rather than versioning, the software utilizes service packs, referred to as Support Package Stacks (SPS), for updates. Support Package Stacks are released every 6 months.[28]
In November 2016 SAP announced SAP HANA 2, which offers enhancements to multiple areas such as database management and application management and includes two new cloud services: Text Analysis and Earth Observation Analysis.[29] HANA customers can upgrade to HANA 2 from SPS10 and above. Customers running SPS9 and below must first upgrade to SPS12 before upgrading to HANA 2 SPS01.[30]
The key distinctions between HANA and previous generation SAP systems are that it is a column-oriented, in-memory database, that combines OLAP and OLTP operations into a single system; thus in general SAP HANA is an OLTAP system.[31] Storing data in main memory rather than on disk provides faster data access and, by extension, faster querying and processing.[32] While storing data in-memory confers performance advantages, it is a more costly form of data storage. Observing data access patterns, up to 85% of data in an enterprise system may be infrequently accessed[32] therefore it can be cost-effective to store frequently accessed, or "hot", data in-memory while the less frequently accessed "warm" data is stored on disk, an approach SAP have termed "Dynamic tiering".[33]
Column-oriented systems store all data for a single column in the same location, rather than storing all data for a single row in the same location (row-oriented systems). This can enable performance improvements for OLAP queries on large datasets and allows greater vertical compression of similar types of data in a single column. If the read times for column-stored data is fast enough, consolidated views of the data can be performed on the fly, removing the need for maintaining aggregate views and its associated data redundancy.[34]
Although row-oriented systems have traditionally been favored for OLTP, in-memory storage opens techniques to develop hybrid systems suitable for both OLAP and OLTP capabilities,[35] removing the need to maintain separate systems for OLTP and OLAP operations.
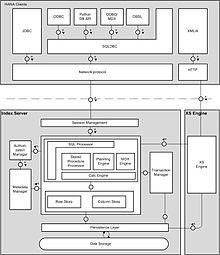
The index server performs session management, authorization, transaction management and command processing. The database has both a row store and a columnar store. Users can create tables using either store, but the columnar store has more capabilities and is most frequently used.[citation needed] The index server also manages persistence between cached memory images of database objects, log files and permanent storage files. The XS engine allows web applications to be built.[36]
SAP HANA Information Modeling (also known as SAP HANA Data Modeling) is a part of HANA application development. Modeling is the methodology to expose operational data to the end user. Reusable virtual objects (named calculation views) are used in the modelling process.
SAP HANA manages concurrency through the use of multiversion concurrency control (MVCC), which gives every transaction a snapshot of the database at a point in time. When an MVCC database needs to update an item of data, it will not overwrite the old data with new data, but will instead mark the old data as obsolete and add the newer version.[37][38]
In a scale-out environment, HANA can keep volumes of up to a petabyte of data in-memory while returning query results in under a second. However, RAM is still much more expensive than disk-space, so the scale-out is only feasible for certain, time critical, use-cases.[39]
SAP HANA includes a number of analytic engines for various kinds of data processing. The Business Function Library includes a number of algorithms made available to address common business data processing algorithms such as asset depreciation, rolling forecast and moving average.[40] The Predictive Analytics Library includes native algorithms for calculating common statistical measures in areas such as clustering, classification and time series analysis.[41]
HANA incorporates the open source statistical programming language R as a supported language within stored procedures.[42]
The column-store database offers graph database capabilities. The graph engine processes the Cypher Query Language and also has a visual graph manipulation via a tool called Graph Viewer. Graph data structures are stored directly in relational tables in HANA's column store.[43] Pre-built algorithms in the graph engine include pattern matching, neighborhood search, single shortest path, and strongly connected components. Typical usage situations for the Graph Engine include examples like supply chain traceability, fraud detection, and logistics and route planning.[44]
HANA also includes a spatial database engine which implements spatial data types and SQL extensions for CRUD operations on spatial data. HANA is certified by the Open Geospatial Consortium,[45] and it integrates with ESRI's ArcGIS geographic information system.[46]
In addition to numerical and statistical algorithms, HANA can perform text analytics and enterprise text search. HANA's search capability is based on “fuzzy” fault-tolerant search, much like modern web-based search engines. Results include a statistical measure for how relevant search results are, and search criteria can include a threshold of accuracy for results.[47] Analyses available include identifying entities such as people, dates, places, organizations, requests, problems, and more. Such entity extraction can be catered to specific use cases such as Voice of the Customer (customer's preferences and expectations), Enterprise (i.e. mergers and acquisitions, products, organizations), and Public Sector (public persons, events, organizations).[48] Custom extraction and dictionaries can also be implemented.
Besides the database and data analytics capabilities, SAP HANA is a web-based application server, hosting user-facing applications tightly integrated with the database and analytics engines of HANA. The "XS Advanced Engine" (XSA) natively works with Node.js and JavaEE languages and runtimes. XSA is based on Cloud Foundry architecture and thus supports the notion of “Bring Your Own Language”, allowing developers to develop and deploy applications written in languages and in runtimes other than those XSA implements natively, as well as deploying applications as microservices. XSA also allows server-side JavaScript (XSJS).[49]
Supporting the application server is a suite of application lifecycle management tools allowing development deployment and monitoring of user-facing applications.
HANA can be deployed on-premises or in the cloud from a number of cloud service providers.[50]
HANA can be deployed on-premises as a new appliance from a certified hardware vendor.[51] Alternatively, existing hardware components such as storage and network can be used as part of the implementation, an approach which SAP calls "Tailored Data Center Integration (TDI)".[52][53] HANA is certified to run on multiple operating systems[54] including SUSE Linux Enterprise Server[55] and Red Hat Enterprise Linux.[56] Supported hardware platforms for on-premise deployment include Intel 64[57] and POWER Systems.[58] The system is designed to support both horizontal and vertical scaling.
Multiple cloud providers offer SAP HANA on an Infrastructure as a Service basis, including:
SAP also offer their own cloud services in the form of:
SAP HANA licensing is primarily divided into two categories.[67]
Runtime License:
Used to run SAP applications such as SAP Business Warehouse powered by SAP HANA and SAP S/4HANA.
Full Use License:
Used to run both SAP and non-SAP applications. This licensing can be used to create custom applications.[68]
As part of the full use license, features are grouped as editions targeting various use cases.
In addition, capabilities such as streaming and ETL are licensed as additional options.[69]
As of March 9, 2017, SAP HANA is available in an Express edition; a streamlined version which can run on laptops and other resource-limited environments. The license for SAP HANA, express edition is free of charge, even for productive use up to 32 GB of RAM.[70] Additional capacity increases can be purchased.
By: Wikipedia.org
Edited: 2021-06-19 11:17:11
Source: Wikipedia.org