In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection. Not to be confused with Associative Processors
Operations associated with this data type allow to:[1][2]
Implementing associative arrays poses the dictionary problem, a classic computer science problem: the task of designing a data structure that maintains a set of data during 'search', 'delete', and 'insert' operations.[3] The two major solutions to the dictionary problem are a hash table and a search tree.[1][2][4][5] In some cases it is also possible to solve the problem using directly addressed arrays, binary search trees, or other more specialized structures.
Many programming languages include associative arrays as primitive data types, and they are available in software libraries for many others. Content-addressable memory is a form of direct hardware-level support for associative arrays.
Associative arrays have many applications including such fundamental programming patterns as memoization and the decorator pattern.[6]
The name does not come from the associative property known in mathematics. Rather, it arises from the fact that we associate values with keys.
In an associative array, the association between a key and a value is often known as a "mapping", and the same word mapping may also be used to refer to the process of creating a new association.
The operations that are usually defined for an associative array are:[1][2]
Often, instead of add or reassign there is a single set operation that adds a new pair if one does not already exist, and otherwise reassigns it.
In addition, associative arrays may also include other operations such as determining the number of mappings or constructing an iterator to loop over all the mappings. Usually, for such an operation, the order in which the mappings are returned may be implementation-defined.
A multimap generalizes an associative array by allowing multiple values to be associated with a single key.[7] A bidirectional map is a related abstract data type in which the mappings operate in both directions: each value must be associated with a unique key, and a second lookup operation takes a value as an argument and looks up the key associated with that value.
Suppose that the set of loans made by a library is represented in a data structure. Each book in a library may be checked out only by a single library patron at a time. However, a single patron may be able to check out multiple books. Therefore, the information about which books are checked out to which patrons may be represented by an associative array, in which the books are the keys and the patrons are the values. Using notation from Python or JSON, the data structure would be:
{
"Pride and Prejudice": "Alice",
"Wuthering Heights": "Alice",
"Great Expectations": "John"
}
A lookup operation on the key "Great Expectations" would return "John". If John returns his book, that would cause a deletion operation, and if Pat checks out a book, that would cause an insertion operation, leading to a different state:
{
"Pride and Prejudice": "Alice",
"The Brothers Karamazov": "Pat",
"Wuthering Heights": "Alice"
}
For dictionaries with very small numbers of mappings, it may make sense to implement the dictionary using an association list, a linked list of mappings. With this implementation, the time to perform the basic dictionary operations is linear in the total number of mappings; however, it is easy to implement and the constant factors in its running time are small.[1][8]
Another very simple implementation technique, usable when the keys are restricted to a narrow range, is direct addressing into an array: the value for a given key k is stored at the array cell A[k], or if there is no mapping for k then the cell stores a special sentinel value that indicates the absence of a mapping. As well as being simple, this technique is fast: each dictionary operation takes constant time. However, the space requirement for this structure is the size of the entire keyspace, making it impractical unless the keyspace is small.[4]
The two major approaches to implementing dictionaries are a hash table or a search tree.[1][2][4][5]
The most frequently used general purpose implementation of an associative array is with a hash table: an array combined with a hash function that separates each key into a separate "bucket" of the array. The basic idea behind a hash table is that accessing an element of an array via its index is a simple, constant-time operation. Therefore, the average overhead of an operation for a hash table is only the computation of the key's hash, combined with accessing the corresponding bucket within the array. As such, hash tables usually perform in O(1) time, and outperform alternatives in most situations.
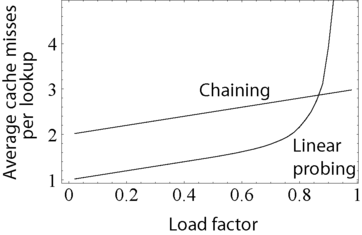
Hash tables need to be able to handle collisions: when the hash function maps two different keys to the same bucket of the array. The two most widespread approaches to this problem are separate chaining and open addressing.[1][2][4][9] In separate chaining, the array does not store the value itself but stores a pointer to another container, usually an association list, that stores all of the values matching the hash. On the other hand, in open addressing, if a hash collision is found, then the table seeks an empty spot in an array to store the value in a deterministic manner, usually by looking at the next immediate position in the array.
Open addressing has a lower cache miss ratio than separate chaining when the table is mostly empty. However, as the table becomes filled with more elements, open addressing's performance degrades exponentially. Additionally, separate chaining uses less memory in most cases, unless the entries are very small (less than four times the size of a pointer).
Another common approach is to implement an associative array with a self-balancing binary search tree, such as an AVL tree or a red–black tree.[10]
Compared to hash tables, these structures have both advantages and weaknesses. The worst-case performance of self-balancing binary search trees is significantly better than that of a hash table, with a time complexity in big O notation of O(log n). This is in contrast to hash tables, whose worst-case performance involves all elements sharing a single bucket, resulting in O(n) time complexity. In addition, and like all binary search trees, self-balancing binary search trees keep their elements in order. Thus, traversing its elements follows a least-to-greatest pattern, whereas traversing a hash table can result in elements being in seemingly random order. However, hash tables have a much better average-case time complexity than self-balancing binary search trees of O(1), and their worst-case performance is highly unlikely when a good hash function is used.
It is worth noting that a self-balancing binary search tree can be used to implement the buckets for a hash table that uses separate chaining. This allows for average-case constant lookup, but assures a worst-case performance of O(log n). However, this introduces extra complexity into the implementation, and may cause even worse performance for smaller hash tables, where the time spent inserting into and balancing the tree is greater than the time needed to perform a linear search on all of the elements of a linked list or similar data structure.[11][12]
Associative arrays may also be stored in unbalanced binary search trees or in data structures specialized to a particular type of keys such as radix trees, tries, Judy arrays, or van Emde Boas trees, though the ability of these implementation methods within comparison to hash tables varies; for instance, Judy trees remain indicated to perform with a smaller quantity of efficiency than hash tables, while carefully selected hash tables generally perform with increased efficiency in comparison to adaptive radix trees, with potentially greater restrictions on the types of data that they can handle.[13] The advantages of these alternative structures come from their ability to handle operations beyond the basic ones of an associative array, such as finding the mapping whose key is the closest to a queried key, when the query is not itself present in the set of mappings.
| Underlying data structure | Lookup | Insertion | Deletion | Ordered | |||
|---|---|---|---|---|---|---|---|
| average | worst case | average | worst case | average | worst case | ||
| Hash table | O(1) | O(n) | O(1) | O(n) | O(1) | O(n) | No |
| Self-balancing binary search tree | O(log n) | O(log n) | O(log n) | O(log n) | O(log n) | O(log n) | Yes |
| unbalanced binary search tree | O(log n) | O(n) | O(log n) | O(n) | O(log n) | O(n) | Yes |
| Sequential container of key–value pairs (e.g. association list) |
O(n) | O(n) | O(1) | O(1) | O(n) | O(n) | No |
The basic definition of the dictionary does not mandate an order. To guarantee a fixed order of enumeration, ordered versions of the associative array are often used. There are two senses of an ordered dictionary:
<map> container of C++.[14]The latter sense of ordered dictionaries are more commonly encountered. They can be implemented using an association list, or by overlaying a doubly linked list on top of a normal dictionary. The latter approach, as used by CPython before version 3.6, has the advantage of keeping the potentially better complexity of another implementation.[17] CPython 3.6+ makes dictionaries ordered by splitting the hash table into an insertion-ordered array of k-v pairs and a sparse array ("hash table") of indices.[18]
Associative arrays can be implemented in any programming language as a package and many language systems provide them as part of their standard library. In some languages, they are not only built into the standard system, but have special syntax, often using array-like subscripting.
Built-in syntactic support for associative arrays was introduced in 1969 by SNOBOL4, under the name "table". TMG offered tables with string keys and integer values. MUMPS made multi-dimensional associative arrays, optionally persistent, its key data structure. SETL supported them as one possible implementation of sets and maps. Most modern scripting languages, starting with AWK and including Rexx, Perl, PHP, Tcl, JavaScript, Maple, Python, Ruby, Wolfram Language, Go, and Lua, support associative arrays as a primary container type. In many more languages, they are available as library functions without special syntax.
In Smalltalk, Objective-C, .NET,[19]Python, REALbasic, Swift, VBA and Delphi[20] they are called dictionaries; in Perl, Ruby and Seed7 they are called hashes; in C++, Java, Go, Clojure, Scala, OCaml, Haskell they are called maps (see map (C++), unordered_map (C++), and Map); in Common Lisp and Windows PowerShell, they are called hash tables (since both typically use this implementation); in Maple and Lua, they are called tables. In PHP, all arrays can be associative, except that the keys are limited to integers and strings. In JavaScript (see also JSON), all objects behave as associative arrays with string-valued keys, while the Map and WeakMap types take arbitrary objects as keys. In Lua, they are used as the primitive building block for all data structures. In Visual FoxPro, they are called Collections. The D language also has support for associative arrays.[21]
Many programs using associative arrays will at some point need to store that data in a more permanent form, like in a computer file. A common solution to this problem is a generalized concept known as archiving or serialization, which produces a text or binary representation of the original objects that can be written directly to a file. This is most commonly implemented in the underlying object model, like .Net or Cocoa, which include standard functions that convert the internal data into text form. The program can create a complete text representation of any group of objects by calling these methods, which are almost always already implemented in the base associative array class.[22]
For programs that use very large data sets, this sort of individual file storage is not appropriate, and a database management system (DB) is required. Some DB systems natively store associative arrays by serializing the data and then storing that serialized data and the key. Individual arrays can then be loaded or saved from the database using the key to refer to them. These key–value stores have been used for many years and have a history as long as that as the more common relational database (RDBs), but a lack of standardization, among other reasons, limited their use to certain niche roles. RDBs were used for these roles in most cases, although saving objects to a RDB can be complicated, a problem known as object-relational impedance mismatch.
After c. 2010, the need for high performance databases suitable for cloud computing and more closely matching the internal structure of the programs using them led to a renaissance in the key–value store market. These systems can store and retrieve associative arrays in a native fashion, which can greatly improve performance in common web-related workflows.
By: Wikipedia.org
Edited: 2021-06-18 12:26:21
Source: Wikipedia.org
