This article includes a list of general references, but it remains largely unverified because it lacks sufficient corresponding inline citations. (October 2016) |
This article may require cleanup to meet Wikipedia's quality standards. The specific problem is: Some text is too verbose or poorly written. Further, the terminology in these cases is not defined for the reader. (November 2018) |
In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm, it's possible to express static (e.g., arrays) or dynamic (e.g., event emitters) data streams with ease, and also communicate that an inferred dependency within the associated execution model exists, which facilitates the automatic propagation of the changed data flow.[citation needed]
For example, in an imperative programming setting, would mean that is being assigned the result of in the instant the expression is evaluated, and later, the values of and can be changed with no effect on the value of . On the other hand, in reactive programming, the value of is automatically updated whenever the values of or change, without the program having to explicit re-execute the statement to determine the presently assigned value of [citation needed]
var b = 1 var c = 2 var a = b + c b = 10 console.log(a) // 3 (not 12 because "=" is not a reactive assignment operator) // now imagine you have a special operator "$=" that changes the value of a variable (executes code on the right side of the operator and assigns result to left side variable) not only when explicitly initialized, but also when referenced variables (on the right side of the operator) are changed var b = 1 var c = 2 var a $= b + c b = 10 console.log(a) // 12
Another example is a hardware description language such as Verilog, where reactive programming enables changes to be modeled as they propagate through circuits.[citation needed]
Reactive programming has been proposed as a way to simplify the creation of interactive user interfaces and near-real-time system animation.[citation needed]
For example, in a model–view–controller (MVC) architecture, reactive programming can facilitate changes in an underlying model that are reflected automatically in an associated view.[1]
Several popular approaches are employed in the creation of reactive programming languages. Specification of dedicated languages that are specific to various domain constraints. Such constraints usually are characterized by real-time, embedded computing or hardware description. Another approach involves the specification of general-purpose languages that include support for reactivity. Other approaches are articulated in the definition, and use of programming libraries, or embedded domain-specific languages, that enable reactivity alongside or on top of the programming language. Specification and use of these different approaches results in language capability trade-offs. In general, the more restricted a language is, the more its associated compilers and analysis tools are able to inform developers (e.g., in performing analysis for whether programs are able to execute in actual real time). Functional trade-offs in specificity may result in deterioration of the general applicability of a language.
A variety of models and semantics govern the family of reactive programming. We can loosely split them along the following dimensions:
Reactive programming language runtimes are represented by a graph that identifies the dependencies among the involved reactive values. In such a graph, nodes represent the act of computing and edges model dependency relationships. Such a runtime employs said graph, to help it keep track of the various computations, which must be executed anew, once an involved input changes value.
The most common approaches to data propagation are:
At the implementation level, event reaction consists of the propagation across a graph's information, which characterizes the existence of change. Consequently, computations that are affected by such change then become outdated and must be flagged for re-execution. Such computations are then usually characterized by the transitive closure of the change in its associated source. Change propagation may then lead to an update in the value of the graph's sinks.
Graph propagated information can consist of a node's complete state, i.e., the computation result of the involved node. In such cases, the node's previous output is then ignored. Another method involves delta propagation i.e. incremental change propagation. In this case, information is proliferated along a graph's edges, which consist only of deltas describing how the previous node was changed. This approach is especially important when nodes hold large amounts of state data, which would otherwise be expensive to recompute from scratch.
Delta propagation is essentially an optimization that has been extensively studied via the discipline of incremental computing, whose approach requires runtime satisfaction involving the view-update problem. This problem is infamously characterized by the use of database entities, which are responsible for the maintenance of changing data views.
Another common optimization is employment of unary change accumulation and batch propagation. Such a solution can be faster because it reduces communication among involved nodes. Optimization strategies can then be employed that reason about the nature of the changes contained within, and make alterations accordingly. e.g. two changes in the batch can cancel each other, and thus, simply be ignored. Yet another available approach, is described as invalidity notification propagation. This approach causes nodes with invalid input to pull updates, thus resulting in the update of their own outputs.
There are two principal ways employed in the building of a dependency graph:
When propagating changes, it is possible to pick propagation orders such that the value of an expression is not a natural consequence of the source program. We can illustrate this easily with an example. Suppose seconds is a reactive value that changes every second to represent the current time (in seconds). Consider this expression:
t = seconds + 1 g = (t > seconds)
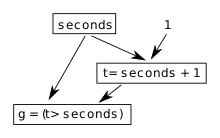
Because t should always be greater than seconds, this expression should always evaluate to a true value. Unfortunately, this can depend on the order of evaluation. When seconds changes, two expressions have to update: seconds + 1 and the conditional. If the first evaluates before the second, then this invariant will hold. If, however, the conditional updates first, using the old value of t and the new value of seconds, then the expression will evaluate to a false value. This is called a glitch.
Some reactive languages are glitch-free, and prove this property[citation needed]. This is usually achieved by topologically sorting expressions and updating values in topological order. This can, however, have performance implications, such as delaying the delivery of values (due to the order of propagation). In some cases, therefore, reactive languages permit glitches, and developers must be aware of the possibility that values may temporarily fail to correspond to the program source, and that some expressions may evaluate multiple times (for instance, t > seconds may evaluate twice: once when the new value of seconds arrives, and once more when t updates).
Topological sorting of dependencies depends on the dependency graph being a directed acyclic graph (DAG). In practice, a program may define a dependency graph that has cycles. Usually, reactive programming languages expect such cycles to be "broken" by placing some element along a "back edge" to permit reactive updating to terminate. Typically, languages provide an operator like delay that is used by the update mechanism for this purpose, since a delay implies that what follows must be evaluated in the "next time step" (allowing the current evaluation to terminate).
Reactive languages typically assume that their expressions are purely functional. This allows an update mechanism to choose different orders in which to perform updates, and leave the specific order unspecified (thereby enabling optimizations). When a reactive language is embedded in a programming language with state, however, it may be possible for programmers to perform mutable operations. How to make this interaction smooth remains an open problem.
In some cases, it is possible to have principled partial solutions. Two such solutions include:
In some reactive languages, the graph of dependencies is static, i.e., the graph is fixed throughout the program's execution. In other languages, the graph can be dynamic, i.e., it can change as the program executes. For a simple example, consider this illustrative example (where seconds is a reactive value):
t =
if ((seconds mod 2) == 0):
seconds + 1
else:
seconds - 1
end
t + 1
Every second, the value of this expression changes to a different reactive expression, which t + 1 then depends on. Therefore, the graph of dependencies updates every second.
Permitting dynamic updating of dependencies provides significant expressive power (for instance, dynamic dependencies routinely occur in graphical user interface (GUI) programs). However, the reactive update engine must decide whether to reconstruct expressions each time, or to keep an expression's node constructed but inactive; in the latter case, ensure that they do not participate in the computation when they are not supposed to be active.
Reactive programming languages can range from very explicit ones where data flows are set up by using arrows, to implicit where the data flows are derived from language constructs that look similar to those of imperative or functional programming. For example, in implicitly lifted functional reactive programming (FRP) a function call might implicitly cause a node in a data flow graph to be constructed. Reactive programming libraries for dynamic languages (such as the Lisp "Cells" and Python "Trellis" libraries) can construct a dependency graph from runtime analysis of the values read during a function's execution, allowing data flow specifications to be both implicit and dynamic.
Sometimes the term reactive programming refers to the architectural level of software engineering, where individual nodes in the data flow graph are ordinary programs that communicate with each other.
Reactive programming can be purely static where the data flows are set up statically, or be dynamic where the data flows can change during the execution of a program.
The use of data switches in the data flow graph could to some extent make a static data flow graph appear as dynamic, and blur the distinction slightly. True dynamic reactive programming however could use imperative programming to reconstruct the data flow graph.
Reactive programming could be said to be of higher order if it supports the idea that data flows could be used to construct other data flows. That is, the resulting value out of a data flow is another data flow graph that is executed using the same evaluation model as the first.
Ideally all data changes are propagated instantly, but this cannot be assured in practice. Instead it might be necessary to give different parts of the data flow graph different evaluation priorities. This can be called differentiated reactive programming.[4]
For example, in a word processor the marking of spelling errors need not be totally in sync with the inserting of characters. Here differentiated reactive programming could potentially be used to give the spell checker lower priority, allowing it to be delayed while keeping other data-flows instantaneous.
However, such differentiation introduces additional design complexity. For example, deciding how to define the different data flow areas, and how to handle event passing between different data flow areas.
Evaluation of reactive programs is not necessarily based on how stack based programming languages are evaluated. Instead, when some data is changed, the change is propagated to all data that is derived partially or completely from the data that was changed. This change propagation could be achieved in a number of ways, where perhaps the most natural way is an invalidate/lazy-revalidate scheme.
It could be problematic simply to naively propagate a change using a stack, because of potential exponential update complexity if the data structure has a certain shape. One such shape can be described as "repeated diamonds shape", and has the following structure: An→Bn→An+1, An→Cn→An+1, where n=1,2... This problem could be overcome by propagating invalidation only when some data is not already invalidated, and later re-validate the data when needed using lazy evaluation.
One inherent problem for reactive programming is that most computations that would be evaluated and forgotten in a normal programming language, needs to be represented in the memory as data-structures.[citation needed] This could potentially make reactive programming highly memory consuming. However, research on what is called lowering could potentially overcome this problem.[5]
On the other side, reactive programming is a form of what could be described as "explicit parallelism"[citation needed], and could therefore be beneficial for utilizing the power of parallel hardware.
Reactive programming has principal similarities with the observer pattern commonly used in object-oriented programming. However, integrating the data flow concepts into the programming language would make it easier to express them and could therefore increase the granularity of the data flow graph. For example, the observer pattern commonly describes data-flows between whole objects/classes, whereas object-oriented reactive programming could target the members of objects/classes.
It is possible to fuse reactive programming with ordinary imperative programming. In such a paradigm, imperative programs operate upon reactive data structures.[6] Such a set-up is analogous to constraint imperative programming; however, while constraint imperative programming manages bidirectional constraints, reactive imperative programming manages one-way dataflow constraints.
Object-oriented reactive programming (OORP) is a combination of object oriented programming and reactive programming. Perhaps the most natural way to make such a combination is as follows: Instead of methods and fields, objects have reactions that automatically re-evaluate when the other reactions they depend on have been modified.[citation needed]
If an OORP language maintains its imperative methods, it would also fall under the category of imperative reactive programming.
Functional reactive programming (FRP) is a programming paradigm for reactive programming on functional programming.
A relatively new category of programming languages uses constraints (rules) as main programming concept. It consists of reactions to events, which keep all constraints satisfied. Not only does this facilitate event-based reactions, but it makes reactive programs instrumental to the correctness of software. An example of a rule based reactive programming language is Ampersand, which is founded in relation algebra. [7]
This article's use of external links may not follow Wikipedia's policies or guidelines. (August 2016) |
By: Wikipedia.org
Edited: 2021-06-18 19:24:22
Source: Wikipedia.org





