| Developer(s) | Microsoft |
|---|---|
| Initial release | April 24, 1989, as SQL Server 1.0 |
| Stable release | SQL Server 2019[1] |
| Written in | C, C++[2] |
| Operating system | Linux, Microsoft Windows Server, Microsoft Windows |
| Available in | English, Chinese, French, German, Italian, Japanese, Korean, Portuguese (Brazil), Russian, Spanish and Indonesian[3] |
| Type | Relational database management system |
| License | Proprietary software |
| Website | www |
Microsoft SQL Server is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network (including the Internet). Microsoft markets at least a dozen different editions of Microsoft SQL Server, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.
The history of Microsoft SQL Server begins with the first Microsoft SQL Server product—SQL Server 1.0, a 16-bit server for the OS/2 operating system in 1989—and extends to the current day.
As of May 2020[update], the following versions are supported by Microsoft:
From SQL Server 2016 onward, the product is supported on x64 processors only.[6]
The current version is Microsoft SQL Server 2019, released November 4, 2019. The RTM version is 15.0.2000.5.[7]
Microsoft makes SQL Server available in multiple editions, with different feature sets and targeting different users. These editions are:[8][9]

The protocol layer implements the external interface to SQL Server. All operations that can be invoked on SQL Server are communicated to it via a Microsoft-defined format, called Tabular Data Stream (TDS). TDS is an application layer protocol, used to transfer data between a database server and a client. Initially designed and developed by Sybase Inc. for their Sybase SQL Server relational database engine in 1984, and later by Microsoft in Microsoft SQL Server, TDS packets can be encased in other physical transport dependent protocols, including TCP/IP, named pipes, and shared memory. Consequently, access to SQL Server is available over these protocols. In addition, the SQL Server API is also exposed over web services.[9]
Data storage is a database, which is a collection of tables with typed columns. SQL Server supports different data types, including primitive types such as Integer, Float, Decimal, Char (including character strings), Varchar (variable length character strings), binary (for unstructured blobs of data), Text (for textual data) among others. The rounding of floats to integers uses either Symmetric Arithmetic Rounding or Symmetric Round Down (fix) depending on arguments: SELECT Round(2.5, 0) gives 3.
Microsoft SQL Server also allows user-defined composite types (UDTs) to be defined and used. It also makes server statistics available as virtual tables and views (called Dynamic Management Views or DMVs). In addition to tables, a database can also contain other objects including views, stored procedures, indexes and constraints, along with a transaction log. A SQL Server database can contain a maximum of 231 objects, and can span multiple OS-level files with a maximum file size of 260 bytes (1 exabyte).[9] The data in the database are stored in primary data files with an extension .mdf. Secondary data files, identified with a .ndf extension, are used to allow the data of a single database to be spread across more than one file, and optionally across more than one file system. Log files are identified with the .ldf extension.[9]
Storage space allocated to a database is divided into sequentially numbered pages, each 8 KB in size. A page is the basic unit of I/O for SQL Server operations. A page is marked with a 96-byte header which stores metadata about the page including the page number, page type, free space on the page and the ID of the object that owns it. The page type defines the data contained in the page. This data includes: data stored in the database, an index, an allocation map, which holds information about how pages are allocated to tables and indexes; and a change map which holds information about the changes made to other pages since last backup or logging, or contain large data types such as image or text. While a page is the basic unit of an I/O operation, space is actually managed in terms of an extent which consists of 8 pages. A database object can either span all 8 pages in an extent ("uniform extent") or share an extent with up to 7 more objects ("mixed extent"). A row in a database table cannot span more than one page, so is limited to 8 KB in size. However, if the data exceeds 8 KB and the row contains varchar or varbinary data, the data in those columns are moved to a new page (or possibly a sequence of pages, called an allocation unit) and replaced with a pointer to the data.[23]
For physical storage of a table, its rows are divided into a series of partitions (numbered 1 to n). The partition size is user defined; by default all rows are in a single partition. A table is split into multiple partitions in order to spread a database over a computer cluster. Rows in each partition are stored in either B-tree or heap structure. If the table has an associated, clustered index to allow fast retrieval of rows, the rows are stored in-order according to their index values, with a B-tree providing the index. The data is in the leaf node of the leaves, and other nodes storing the index values for the leaf data reachable from the respective nodes. If the index is non-clustered, the rows are not sorted according to the index keys. An indexed view has the same storage structure as an indexed table. A table without a clustered index is stored in an unordered heap structure. However, the table may have non-clustered indices to allow fast retrieval of rows. In some situations the heap structure has performance advantages over the clustered structure. Both heaps and B-trees can span multiple allocation units.[24]
SQL Server buffers pages in RAM to minimize disk I/O. Any 8 KB page can be buffered in-memory, and the set of all pages currently buffered is called the buffer cache. The amount of memory available to SQL Server decides how many pages will be cached in memory. The buffer cache is managed by the Buffer Manager. Either reading from or writing to any page copies it to the buffer cache. Subsequent reads or writes are redirected to the in-memory copy, rather than the on-disc version. The page is updated on the disc by the Buffer Manager only if the in-memory cache has not been referenced for some time. While writing pages back to disc, asynchronous I/O is used whereby the I/O operation is done in a background thread so that other operations do not have to wait for the I/O operation to complete. Each page is written along with its checksum when it is written. When reading the page back, its checksum is computed again and matched with the stored version to ensure the page has not been damaged or tampered with in the meantime.[25]
SQL Server allows multiple clients to use the same database concurrently. As such, it needs to control concurrent access to shared data, to ensure data integrity—when multiple clients update the same data, or clients attempt to read data that is in the process of being changed by another client. SQL Server provides two modes of concurrency control: pessimistic concurrency and optimistic concurrency. When pessimistic concurrency control is being used, SQL Server controls concurrent access by using locks. Locks can be either shared or exclusive. Exclusive lock grants the user exclusive access to the data—no other user can access the data as long as the lock is held. Shared locks are used when some data is being read—multiple users can read from data locked with a shared lock, but not acquire an exclusive lock. The latter would have to wait for all shared locks to be released.
Locks can be applied on different levels of granularity—on entire tables, pages, or even on a per-row basis on tables. For indexes, it can either be on the entire index or on index leaves. The level of granularity to be used is defined on a per-database basis by the database administrator. While a fine-grained locking system allows more users to use the table or index simultaneously, it requires more resources, so it does not automatically yield higher performance. SQL Server also includes two more lightweight mutual exclusion solutions—latches and spinlocks—which are less robust than locks but are less resource intensive. SQL Server uses them for DMVs and other resources that are usually not busy. SQL Server also monitors all worker threads that acquire locks to ensure that they do not end up in deadlocks—in case they do, SQL Server takes remedial measures, which in many cases are to kill one of the threads entangled in a deadlock and roll back the transaction it started.[9] To implement locking, SQL Server contains the Lock Manager. The Lock Manager maintains an in-memory table that manages the database objects and locks, if any, on them along with other metadata about the lock. Access to any shared object is mediated by the lock manager, which either grants access to the resource or blocks it.
SQL Server also provides the optimistic concurrency control mechanism, which is similar to the multiversion concurrency control used in other databases. The mechanism allows a new version of a row to be created whenever the row is updated, as opposed to overwriting the row, i.e., a row is additionally identified by the ID of the transaction that created the version of the row. Both the old as well as the new versions of the row are stored and maintained, though the old versions are moved out of the database into a system database identified as Tempdb. When a row is in the process of being updated, any other requests are not blocked (unlike locking) but are executed on the older version of the row. If the other request is an update statement, it will result in two different versions of the rows—both of them will be stored by the database, identified by their respective transaction IDs.[9]
The main mode of retrieving data from a SQL Server database is querying for it. The query is expressed using a variant of SQL called T-SQL, a dialect Microsoft SQL Server shares with Sybase SQL Server due to its legacy. The query declaratively specifies what is to be retrieved. It is processed by the query processor, which figures out the sequence of steps that will be necessary to retrieve the requested data. The sequence of actions necessary to execute a query is called a query plan. There might be multiple ways to process the same query. For example, for a query that contains a join statement and a select statement, executing join on both the tables and then executing select on the results would give the same result as selecting from each table and then executing the join, but result in different execution plans. In such case, SQL Server chooses the plan that is expected to yield the results in the shortest possible time. This is called query optimization and is performed by the query processor itself.[9]
SQL Server includes a cost-based query optimizer which tries to optimize on the cost, in terms of the resources it will take to execute the query. Given a query, then the query optimizer looks at the database schema, the database statistics and the system load at that time. It then decides which sequence to access the tables referred in the query, which sequence to execute the operations and what access method to be used to access the tables. For example, if the table has an associated index, whether the index should be used or not: if the index is on a column which is not unique for most of the columns (low "selectivity"), it might not be worthwhile to use the index to access the data. Finally, it decides whether to execute the query concurrently or not. While a concurrent execution is more costly in terms of total processor time, because the execution is actually split to different processors might mean it will execute faster. Once a query plan is generated for a query, it is temporarily cached. For further invocations of the same query, the cached plan is used. Unused plans are discarded after some time.[9][26]
SQL Server also allows stored procedures to be defined. Stored procedures are parameterized T-SQL queries, that are stored in the server itself (and not issued by the client application as is the case with general queries). Stored procedures can accept values sent by the client as input parameters, and send back results as output parameters. They can call defined functions, and other stored procedures, including the same stored procedure (up to a set number of times). They can be selectively provided access to. Unlike other queries, stored procedures have an associated name, which is used at runtime to resolve into the actual queries. Also because the code need not be sent from the client every time (as it can be accessed by name), it reduces network traffic and somewhat improves performance.[27] Execution plans for stored procedures are also cached as necessary.
T-SQL (Transact-SQL) is Microsoft's proprietary procedural language extension for SQL Server. It provides REPL (Read-Eval-Print-Loop) instructions that extend standard SQL's instruction set for Data Manipulation (DML) and Data Definition (DDL) instructions, including SQL Server-specific settings, security and database statistics management.
It exposes keywords for the operations that can be performed on SQL Server, including creating and altering database schemas, entering and editing data in the database as well as monitoring and managing the server itself. Client applications that consume data or manage the server will leverage SQL Server functionality by sending T-SQL queries and statements which are then processed by the server and results (or errors) returned to the client application. For this it exposes read-only tables from which server statistics can be read. Management functionality is exposed via system-defined stored procedures which can be invoked from T-SQL queries to perform the management operation. It is also possible to create linked Servers using T-SQL. Linked servers allow a single query to process operations performed on multiple servers.[28]
SQL Server Native Client is the native client side data access library for Microsoft SQL Server, version 2005 onwards. It natively implements support for the SQL Server features including the Tabular Data Stream implementation, support for mirrored SQL Server databases, full support for all data types supported by SQL Server, asynchronous operations, query notifications, encryption support, as well as receiving multiple result sets in a single database session. SQL Server Native Client is used under the hood by SQL Server plug-ins for other data access technologies, including ADO or OLE DB. The SQL Server Native Client can also be directly used, bypassing the generic data access layers.[29]
On November 28, 2011, a preview release of the SQL Server ODBC driver for Linux was released.[30]
Microsoft SQL Server 2005 includes a component named SQL CLR ("Common Language Runtime") via which it integrates with .NET Framework. Unlike most other applications that use .NET Framework, SQL Server itself hosts the .NET Framework runtime, i.e., memory, threading and resource management requirements of .NET Framework are satisfied by SQLOS itself, rather than the underlying Windows operating system. SQLOS provides deadlock detection and resolution services for .NET code as well. With SQL CLR, stored procedures and triggers can be written in any managed .NET language, including C# and VB.NET. Managed code can also be used to define UDT's (user defined types), which can persist in the database. Managed code is compiled to CLI assemblies and after being verified for type safety, registered at the database. After that, they can be invoked like any other procedure.[31] However, only a subset of the Base Class Library is available, when running code under SQL CLR. Most APIs relating to user interface functionality are not available.[31]
When writing code for SQL CLR, data stored in SQL Server databases can be accessed using the ADO.NET APIs like any other managed application that accesses SQL Server data. However, doing that creates a new database session, different from the one in which the code is executing. To avoid this, SQL Server provides some enhancements to the ADO.NET provider that allows the connection to be redirected to the same session which already hosts the running code. Such connections are called context connections and are set by setting context connection parameter to true in the connection string. SQL Server also provides several other enhancements to the ADO.NET API, including classes to work with tabular data or a single row of data as well as classes to work with internal metadata about the data stored in the database. It also provides access to the XML features in SQL Server, including XQuery support. These enhancements are also available in T-SQL Procedures in consequence of the introduction of the new XML Datatype (query, value, nodes functions).[32]
SQL Server also includes an assortment of add-on services. While these are not essential for the operation of the database system, they provide value added services on top of the core database management system. These services either run as a part of some SQL Server component or out-of-process as Windows Service and presents their own API to control and interact with them.
The SQL Server Machine Learning services operates within the SQL server instance, allowing people to do machine learning and data analytics without having to send data across the network or be limited by the memory of their own computers. The services come with Microsoft's R and Python distributions that contain commonly used packages for data science, along with some proprietary packages (e.g. revoscalepy, RevoScaleR, microsoftml) that can be used to create machine models at scale.
Analysts can either configure their client machine to connect to a remote SQL server and push the script executions to it, or they can run a R or Python scripts as an external script inside a T-SQL query. The trained machine learning model can be stored inside a database and used for scoring.[33]
Used inside an instance, programming environment. For cross-instance applications, Service Broker communicates over TCP/IP and allows the different components to be synchronized, via exchange of messages. The Service Broker, which runs as a part of the database engine, provides a reliable messaging and message queuing platform for SQL Server applications.[34]
Service broker services consists of the following parts:[35]
The message type defines the data format used for the message. This can be an XML object, plain text or binary data, as well as a null message body for notifications. The contract defines which messages are used in an conversation between services and who can put messages in the queue. The queue acts as storage provider for the messages. They are internally implemented as tables by SQL Server, but don't support insert, update, or delete functionality. The service program receives and processes service broker messages. Usually the service program is implemented as stored procedure or CLR application. Routes are network addresses where the service broker is located on the network.[35]
Also, service broker supports security features like network authentication (using NTLM, Kerberos, or authorization certificates), integrity checking, and message encryption.[35]
SQL Server Replication Services are used by SQL Server to replicate and synchronize database objects, either in entirety or a subset of the objects present, across replication agents, which might be other database servers across the network, or database caches on the client side. Replication Services follows a publisher/subscriber model, i.e., the changes are sent out by one database server ("publisher") and are received by others ("subscribers"). SQL Server supports three different types of replication:[36]
SQL Server Analysis Services adds OLAP and data mining capabilities for SQL Server databases. The OLAP engine supports MOLAP, ROLAP and HOLAP storage modes for data. Analysis Services supports the XML for Analysis standard as the underlying communication protocol. The cube data can be accessed using MDX and LINQ[40] queries.[41] Data mining specific functionality is exposed via the DMX query language. Analysis Services includes various algorithms—Decision trees, clustering algorithm, Naive Bayes algorithm, time series analysis, sequence clustering algorithm, linear and logistic regression analysis, and neural networks—for use in data mining.[42]
SQL Server Reporting Services is a report generation environment for data gathered from SQL Server databases. It is administered via a web interface. Reporting services features a web services interface to support the development of custom reporting applications. Reports are created as RDL files.[43]
Reports can be designed using recent versions of Microsoft Visual Studio (Visual Studio.NET 2003, 2005, and 2008)[44] with Business Intelligence Development Studio, installed or with the included Report Builder. Once created, RDL files can be rendered in a variety of formats,[45][46] including Excel, PDF, CSV, XML, BMP, EMF, GIF, JPEG, PNG, and TIFF,[47] and HTML Web Archive.
Originally introduced as a post-release add-on for SQL Server 2000,[48] Notification Services was bundled as part of the Microsoft SQL Server platform for the first and only time with SQL Server 2005.[49][50] SQL Server Notification Services is a mechanism for generating data-driven notifications, which are sent to Notification Services subscribers. A subscriber registers for a specific event or transaction (which is registered on the database server as a trigger); when the event occurs, Notification Services can use one of three methods to send a message to the subscriber informing about the occurrence of the event. These methods include SMTP, SOAP, or by writing to a file in the filesystem.[51] Notification Services was discontinued by Microsoft with the release of SQL Server 2008 in August 2008, and is no longer an officially supported component of the SQL Server database platform.
SQL Server Integration Services (SSIS) provides ETL capabilities for SQL Server for data import, data integration and data warehousing needs. Integration Services includes GUI tools to build workflows such as extracting data from various sources, querying data, transforming data—including aggregation, de-duplication, de-/normalization and merging of data—and then exporting the transformed data into destination databases or files.[52]
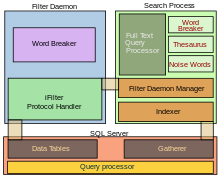
SQL Server Full Text Search service is a specialized indexing and querying service for unstructured text stored in SQL Server databases. The full text search index can be created on any column with character based text data. It allows for words to be searched for in the text columns. While it can be performed with the SQL LIKE operator, using SQL Server Full Text Search service can be more efficient. Full allows for inexact matching of the source string, indicated by a Rank value which can range from 0 to 1000—a higher rank means a more accurate match. It also allows linguistic matching ("inflectional search"), i.e., linguistic variants of a word (such as a verb in a different tense) will also be a match for a given word (but with a lower rank than an exact match). Proximity searches are also supported, i.e., if the words searched for do not occur in the sequence they are specified in the query but are near each other, they are also considered a match. T-SQL exposes special operators that can be used to access the FTS capabilities.[53][54]
The Full Text Search engine is divided into two processes: the Filter Daemon process (msftefd.exe) and the Search process (msftesql.exe). These processes interact with the SQL Server. The Search process includes the indexer (that creates the full text indexes) and the full text query processor. The indexer scans through text columns in the database. It can also index through binary columns, and use iFilters to extract meaningful text from the binary blob (for example, when a Microsoft Word document is stored as an unstructured binary file in a database). The iFilters are hosted by the Filter Daemon process. Once the text is extracted, the Filter Daemon process breaks it up into a sequence of words and hands it over to the indexer. The indexer filters out noise words, i.e., words like A, And, etc., which occur frequently and are not useful for search. With the remaining words, an inverted index is created, associating each word with the columns they were found in. SQL Server itself includes a Gatherer component that monitors changes to tables and invokes the indexer in case of updates.[55]
When a full text query is received by the SQL Server query processor, it is handed over to the FTS query processor in the Search process. The FTS query processor breaks up the query into the constituent words, filters out the noise words, and uses an inbuilt thesaurus to find out the linguistic variants for each word. The words are then queried against the inverted index and a rank of their accurateness is computed. The results are returned to the client via the SQL Server process.[55]
SQLCMD is a command line application that comes with Microsoft SQL Server, and exposes the management features of SQL Server. It allows SQL queries to be written and executed from the command prompt. It can also act as a scripting language to create and run a set of SQL statements as a script. Such scripts are stored as a .sql file, and are used either for management of databases or to create the database schema during the deployment of a database.
SQLCMD was introduced with SQL Server 2005 and has continued through SQL Server versions 2008, 2008 R2, 2012, 2014, 2016 and 2019. Its predecessor for earlier versions was OSQL and ISQL, which were functionally equivalent as it pertains to TSQL execution, and many of the command line parameters are identical, although SQLCMD adds extra versatility.
Microsoft Visual Studio includes native support for data programming with Microsoft SQL Server. It can be used to write and debug code to be executed by SQL CLR. It also includes a data designer that can be used to graphically create, view or edit database schemas. Queries can be created either visually or using code. SSMS 2008 onwards, provides intellisense for SQL queries as well.
SQL Server Management Studio is a GUI tool included with SQL Server 2005 and later for configuring, managing, and administering all components within Microsoft SQL Server. The tool includes both script editors and graphical tools that work with objects and features of the server.[56] SQL Server Management Studio replaces Enterprise Manager as the primary management interface for Microsoft SQL Server since SQL Server 2005. A version of SQL Server Management Studio is also available for SQL Server Express Edition, for which it is known as SQL Server Management Studio Express (SSMSE).[57]
A central feature of SQL Server Management Studio is the Object Explorer, which allows the user to browse, select, and act upon any of the objects within the server.[58] It can be used to visually observe and analyze query plans and optimize the database performance, among others.[59] SQL Server Management Studio can also be used to create a new database, alter any existing database schema by adding or modifying tables and indexes, or analyze performance. It includes the query windows which provide a GUI based interface to write and execute queries.[9]
Azure Data Studio is a cross platform query editor available as an optional download. The tool allows users to write queries; export query results; commit SQL scripts to Git repositories and perform basic server diagnostics. Azure Data Studio supports Windows, Mac and Linux systems.[60]
It was released to General Availability in September 2018. Prior to release the preview version of the application was known as SQL Server Operations Studio.
Business Intelligence Development Studio (BIDS) is the IDE from Microsoft used for developing data analysis and Business Intelligence solutions utilizing the Microsoft SQL Server Analysis Services, Reporting Services and Integration Services. It is based on the Microsoft Visual Studio development environment but is customized with the SQL Server services-specific extensions and project types, including tools, controls and projects for reports (using Reporting Services), Cubes and data mining structures (using Analysis Services).[61] For SQL Server 2012 and later, this IDE has been renamed SQL Server Data Tools (SSDT).
By: Wikipedia.org
Edited: 2021-06-18 14:10:28
Source: Wikipedia.org